
До настоящего времени Частотный словарь русского языка под редакцией Л.Н.Засориной (1977) чаще всего использовался в качестве источника информации о частоте русских слов. Однако, использованный для словаря корпус, по современным стандартам, мал (примерно один миллион слов). Устарел и список слов, т.к. он соответствует частоте применения слов с 20-х до 60-х годов прошлого века. Корпус включает много идеологических источников: произведения Ленина и Калинина, материалы XXII и XXIII съездов КПСС, советские газеты. Слова советский и товарищ входят в первую сотню русских слов, наряду со служебными словами (они встречаются чаще слов где, здесь, ваш); слова партия, революция, коммунистический встречаются чаще, чем назад, около, лучше и т.д. Кроме того, список слов из словаря Засориной не существует в электронном виде.
Кроме того, существует более новое издание: Ольга Ляшевская, Сергей Шаров. Частотный словарь современного русского языка, 2009. 1112 с.
Этот частотный словарь содержит сведения о наиболее употребительных словах современного русского языка. Он создан на основе Национального корпуса русского языка, авторитетного и представительного электронного ресурса. Подкорпус 1950-2007 гг. объемом 92 млн. словоупотреблений включает тексты художественной литературы, средств массовой информации, технические, деловые документы и т.д., а также записи разговорной речи.
Словарь представляет разнообразную статистическую информацию для 50 тыс. слов общей лексики и 3 тыс. имен собственных и аббревиатур. Приводятся частотные списки лексики, характерной для публицистики, устной речи и других функциональных жанров, а также списки наиболее употребительных существительных, прилагательных, глаголов и слов других частей речи.
Заказать этот словарь можно в сетевом книжном магазине Озон.
Разделы страницы об частотном словаре Шарова:
Смотрите также библиографию по лексико-статистическим русским словарям.
- Рубрикация Шаровского словаря
- Статистика использования русских слов
- Сетевые источники
- Списки частотных слов русского языка
- См. также
- Литература
- Смотреть что такое «Списки частотных слов русского языка» в других словарях:
- Для чего нужны частотные словари и почему одни слова важнее других?
- Заглонитель и турмы
- «и», «в», «не», «на»: частотный словарь
- Очевидно, что полезно сперва учить частотные слова, а потом уже редкие: знать слово «собака» куда важнее, чем «самец»или «всадник», и уж тем более, чем «вольвокс» или «рейсфедер».
- Слова, города и всё на свете: закон Ципфа
- Закон Ципфа — один из редких примеров закона, который был открыт на материале языка, а потом нашел применение во множестве других областей.
- Когда пытаются понять, написан ли какой-то текст на человеческом языке или нет, одна из первых проверок, которые стоит сделать, — посмотреть, подчиняется ли текст закону Ципфа.
- Зачем нужны частоты
- В 2007 году директор по исследованиям компании Google Питер Норвиг за несколько часов, проведе–нных в самолете (даже без интернета!), написал программу для исправления опечаток, которая занимает всего 22 строки кода на языке Python и в первую очередь опирается на частотность.
- Частотный словарь русского языка
- Частотный словарь русского языка для детей
- Рубрикация Шаровского словаря
- Статистика использования русских слов
- Сетевые источники
- Для чего нужны частотные словари и почему одни слова важнее других?
- Заглонитель и турмы
- «и», «в», «не», «на»: частотный словарь
- Очевидно, что полезно сперва учить частотные слова, а потом уже редкие: знать слово «собака» куда важнее, чем «самец»или «всадник», и уж тем более, чем «вольвокс» или «рейсфедер».
- Слова, города и всё на свете: закон Ципфа
- Закон Ципфа — один из редких примеров закона, который был открыт на материале языка, а потом нашел применение во множестве других областей.
- Когда пытаются понять, написан ли какой-то текст на человеческом языке или нет, одна из первых проверок, которые стоит сделать, — посмотреть, подчиняется ли текст закону Ципфа.
- Зачем нужны частоты
- В 2007 году директор по исследованиям компании Google Питер Норвиг за несколько часов, проведе–нных в самолете (даже без интернета!), написал программу для исправления опечаток, которая занимает всего 22 строки кода на языке Python и в первую очередь опирается на частотность.
- Списки частотных слов русского языка
- См. также
- Литература
- Смотреть что такое «Списки частотных слов русского языка» в других словарях:
- Частотный словарь русского языка для детей
Рубрикация Шаровского словаря
Для удобства словарь Сергея Шарова разделён на рубрики по сотне слов.
Статистика использования русских слов
Сетевые источники
Ссылки в сети на Шаровский частотный словарь:
Списки частотных слов русского языка
Список самых частотных слов любого языка зависит от того материала, на котором эта частота считалась. В данном случае был использован Национальный корпус русского языка. Кроме того, списки, приведённые ниже, предполагают лемматизацию, то есть приведение всех словоформ к их словарной форме, например, все формы были, буду, бывший приведены к форме быть, что в последнем случае может оспариваться некоторыми лингвистами.
Частоты приведены к чмс (частота на миллион словоформ, ipm, instances per million words), что означает, что слово Москва в среднем встречается 452 раза на один миллион слов текста (на основе материалов НКРЯ). В результате лемматизации все слова приведены к нижнему регистру, включая слова, которые в большинстве случаев пишутся с большой буквы.
Три колонки: существительные, глаголы, прилагательные.
| Частота | Слово |
|---|---|
| 2369 | человек |
| 1529 | время |
| 1490 | год |
| 1195 | дело |
| 1119 | жизнь |
| 1024 | рука |
| 1005 | день |
| 839 | слово |
| 835 | раз |
| 747 | глаз |
| 743 | лицо |
| 724 | место |
| 670 | дом |
| 660 | работа |
| 658 | Россия |
| 624 | друг |
| 622 | сторона |
| 611 | голова |
| 590 | вопрос |
| 550 | сила |
| 543 | мир |
| 529 | случай |
| 503 | ребенок |
| 472 | город |
| 468 | вид |
| 463 | страна |
| 453 | конец |
| 452 | Москва |
| 449 | бог |
| 442 | часть |
| Частота | Слово |
|---|---|
| 8900 | быть |
| 2398 | мочь |
| 2053 | сказать |
| 1492 | говорить |
| 1427 | знать |
| 1291 | есть |
| 1186 | стать |
| 849 | хотеть |
| 793 | иметь |
| 758 | видеть |
| 711 | идти |
| 669 | думать |
| 608 | жить |
| 602 | сделать |
| 561 | делать |
| 505 | пойти |
| 496 | дать |
| 465 | взять |
| 455 | смотреть |
| 453 | спросить |
| 451 | любить |
| 439 | понимать |
| 434 | сидеть |
| 402 | казаться |
| 391 | работать |
| 382 | стоить |
| 381 | прийти |
| 380 | понять |
| 368 | выйти |
| 359 | давать |
| Частота | Слово |
|---|---|
| 876 | новый |
| 554 | последний |
| 473 | русский |
| 456 | хороший |
| 429 | большой |
| 373 | высокий |
| 362 | российский |
| 339 | молодой |
| 339 | великий |
| 326 | старый |
| 317 | главный |
| 312 | общий |
| 308 | маленький |
| 303 | полный |
| 266 | настоящий |
| 265 | разный |
| 263 | белый |
| 258 | государственный |
| 241 | далекий |
| 237 | черный |
| 231 | нужный |
| 226 | известный |
| 224 | советский |
| 223 | целый |
| 213 | живой |
| 210 | сильный |
| 209 | военный |
См. также
Литература
Смотреть что такое «Списки частотных слов русского языка» в других словарях:
Самое длинное слово русского языка — Решение проблемы того, какое слово в русском языке является самым длинным (и даже ответ на вопрос о том, имеет ли вообще эта проблема решение), зависит от нескольких факторов. Содержание 1 Критерии 2 Условия выбора 2.1 Форма слов … Википедия
Национальный корпус русского языка — URL: http://ruscorpora.ru/ Коммерческий: нет Тип сайта: образовательный/научный проект Реги … Википедия
Частотный словарь — (или частотный список) набор слов данного языка (или подъязыка) вместе с информацией о частоте их встречаемости. Словарь может быть отсортирован по частоте, по алфавиту (тогда для каждого слова будет указана его частота), по группам слов… … Википедия
Русский язык — У этого термина существуют и другие значения, см. Русский язык (значения). Русский язык Произношение: ˈruskʲɪj jɪˈzɨk … Википедия
Частотность — термин лексикостатистики, предназначенный для определения наиболее употребительных слов. Расчёт осуществляется по формуле: где Freqx частотность слова «x», Qx количество словоупотреблений слова «x», Qall общее количество словоупотреблений. В… … Википедия
НКРЯ — Национальный корпус русского языка общедоступный для поиска электронный онлайновый корпус русских текстов. Открыт 29 апреля 2004 в Интернете по адресу http://ruscorpora.ru/. Содержание 1 Составители 2 Состав корпуса … Википедия
словарь лингвистический — Словарь, в котором дается разъяснение значения и употребления слов (в отличие от энциклопедического словаря, сообщающего сведения о соответствующих реалиях предметах, явлениях, событиях). Диалектный (областной) словарь. Словарь, содержащий… … Словарь лингвистических терминов
Медицина — I Медицина Медицина система научных знаний и практической деятельности, целями которой являются укрепление и сохранение здоровья, продление жизни людей, предупреждение и лечение болезней человека. Для выполнения этих задач М. изучает строение и… … Медицинская энциклопедия
Для чего нужны частотные словари и почему одни слова важнее других?
Компьютеры стали активно использоваться в лингвистике только в последней четверти XX века. До того ученые, которые изучали язык, по большей части занимались описанием грамматических правил и значений слов, не опираясь на количественные данные. Но когда появилась возможность обрабатывать большие массивы текстов, стало ясно, что мы многое теряем, если не различаем частотные и редкие явления. О том, какую пользу могут принести исследования частотности в языке, специально для «Ножа» рассказывает Александр Пиперски — доцент РГГУ, научный сотрудник НИУ ВШЭ, лауреат премии «Просветитель»–2017.
Заглонитель и турмы
Попробуйте прочитать такой текст на русском языке:
Заглонитель Ланс Оливер чуть не погиб в результате наплочения турма. Он ехал ласкунно на лошади покровнательно от Мэнсфилда (Австралия) и увидел вахню турмов, в которой было кастожно 15 животных. Столенно, ничего бы и не случилось, если бы собака Оливера не начала порочить на вахню.
Один из турмов — старый, крупный лователь, выбатушенный корочением собаки, бросился за ней. Та отпешила скумановаться за лошадью, на которой сидел Оливер. Тогда турм бросился уже на Оливера. Он схватил подвешенца отмаленными твинами за плечи и вытокнул его на землю.
Цитируется по: Р. М. Фрумкина. Психолингвистика. М., 2001
Вы встретили множество незнакомых слов, но нет сомнений, что вы в целом поняли, о чем здесь говорится, и даже можете пересказать содержание. А сконструирован этот текст очень простым способом: взят нормальный текст, но сохранены в нем только самые частотные слова, а все редкие заменены вымышленными. Вот оригинал этой истории:
Скотовод Ланс Оливер чуть не погиб в результате нападения кенгуру. Он ехал верхом на лошади неподалеку от Мэнсфилда (Австралия) и увидел стадо кенгуру, в котором было примерно 15 животных. Возможно, ничего бы и не случилось, если бы собака Оливера не начала лаять на стадо.
Один из кенгуру — старый крупный самец, раздраженный лаем собаки, бросился за ней. Та попыталась укрыться за лошадью, на которой сидел Оливер. Тогда кенгуру бросился уже на Оливера. Он схватил всадника передними лапами за плечи и сбросил его на землю.
Получается, для того, чтобы понимать человеческий язык, достаточно неполных знаний. Более того, полных знаний и не бывает: никто из нас не может знать все слова и гарантировать, что поймет от начала и до конца любое встретившееся ему предложение.
«и», «в», «не», «на»: частотный словарь
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке? Ну или не понимать, а хотя бы опознавать 20 % слов в тексте.
Очевидно, что полезно сперва учить частотные слова, а потом уже редкие: знать слово «собака» куда важнее, чем «самец» или «всадник», и уж тем более, чем «вольвокс» или «рейсфедер».
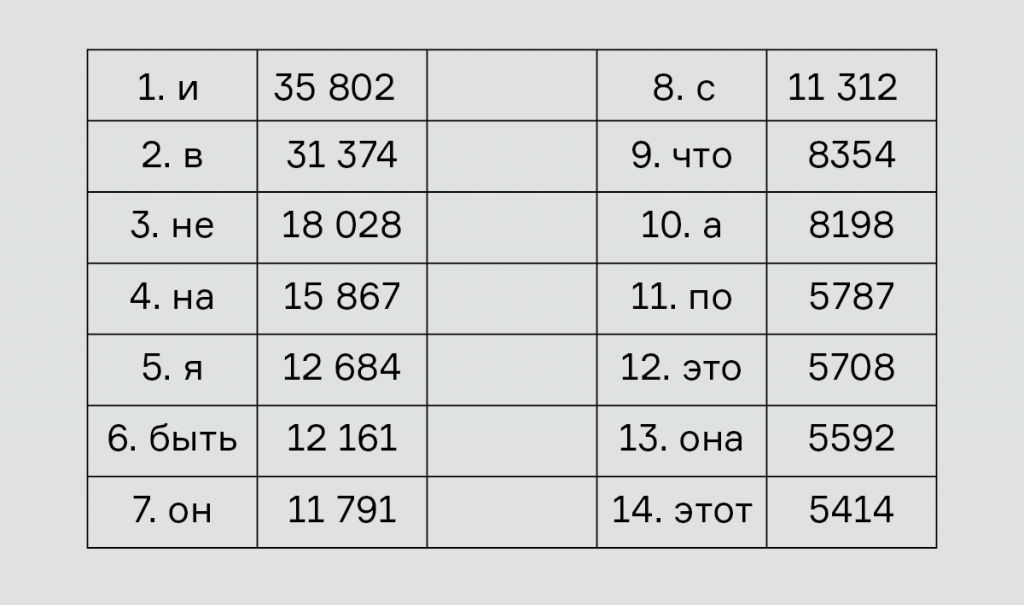
Самый популярный частотный словарь для русского языка в 2009 году создали Ольга Ляшевская и Сергей Шаров. Он свободно доступен на сайте Института русского языка им. В. В. Виноградова. Первое по частотности русское слово — это слово «и», за ним следуют «в», «не», «на», «я» и т. д. — вот и будем запоминать их подряд по этому списку:
Вернемся к предложению, в котором мы поставили перед собой задачу:
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке?
В нем 20 слов, а значит, 20 % от них — это 4 слова. А теперь присмотритесь внимательно: оказывается, выучив первые 14 слов из частотного словаря, мы и узнаем в этом тексте 4 слова — «что», «и», «на» и «этом». Желанный результат достигнут: 20 % текста поняты (хотя до смысла, конечно, еще очень далеко).
В частотном словаре каждому слову приписано число, которое показывает, сколько раз это слово встретится, если мы возьмем текст длиной 1 миллион слов. Слово «и» мы в таком тексте увидим примерно 35 802 раза, слово «в» — 31 374 раза и т. д. Если сложить частоты первых 14 слов, то окажется, что они покроют 188 072 слова из миллиона — то есть почти те самые 20 %, к которым мы стремились. Чтобы выйти за 200 000, к ним надо добавить еще три слова («к», «но» и «они»). А чтобы понять 10 % текста, достаточно и вовсе 4 слов.
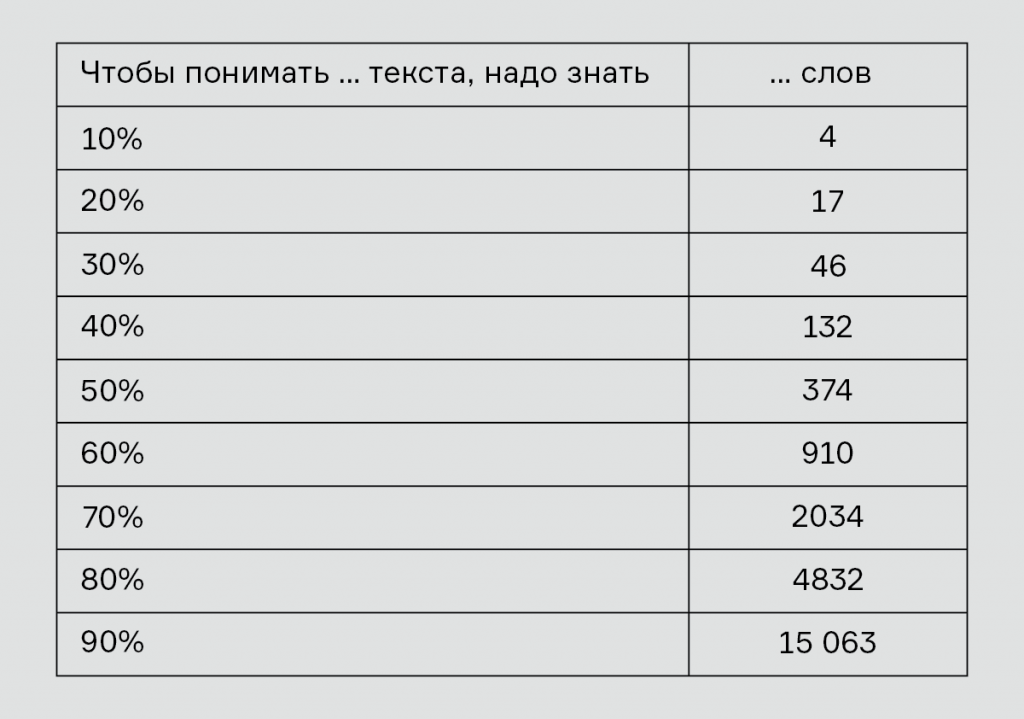
Вот полные списки слов, которых хватит, чтобы понять 10 %, 20 %, 30 % и 40 % текста на русском языке:

Видно, что на первые 10 % у иностранца уйдет совсем мало усилий. На следующие 10 % понадобится еще 13 слов; чтобы достигнуть 30-процентного понимания, придется добавить 29 слов, а чтобы добраться до 40 % — 86 слов. Чем дальше мы идем по частотному списку, тем менее полезно нам каждое следующее слово:
Иначе говоря, в любом языке есть совсем немного высокочастотных слов и много низкочастотных. Например, 1 раз на миллион слов, согласно словарю Ляшевской и Шарова, встретится 1478 слов; среди них — «резвость», «увильнуть», «боезапас», «сызнова», «картографирование». Ясно, что это совсем не то, что надо учить в первую очередь.
Слова, города и всё на свете: закон Ципфа
Частоты слов подчиняются простой математической закономерности, которую в середине XX века открыл американец Джордж Кингсли Ципф (1902–1950).
 Источник
Источник
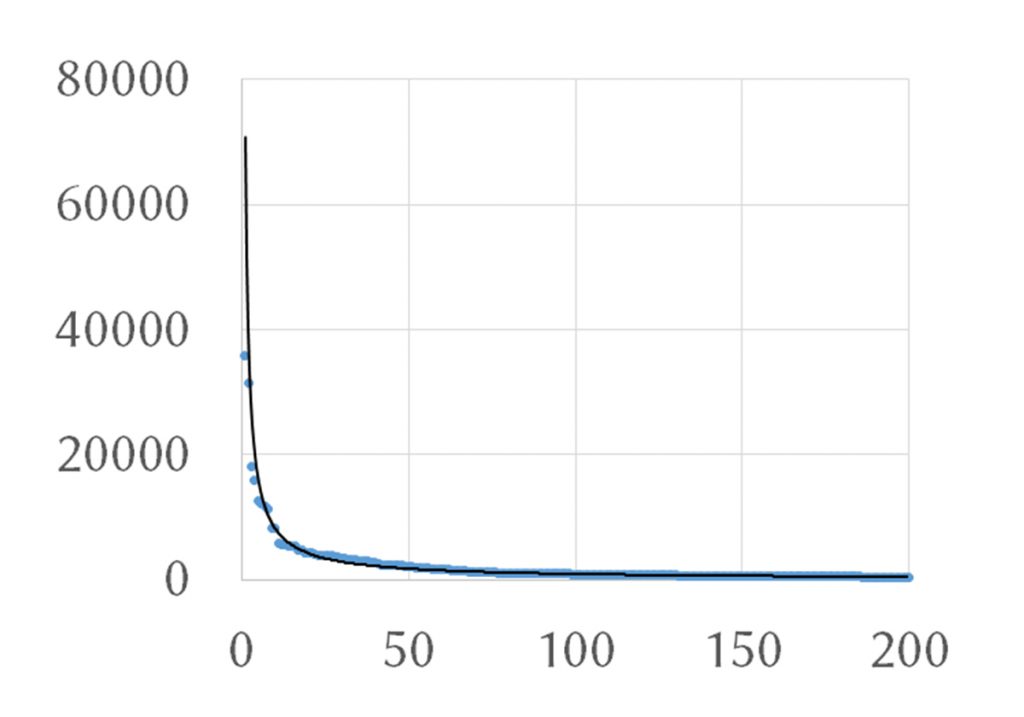
Он сформулировал такую зависимость, которая получила название «закон Ципфа»: частотность слова обратно пропорциональна номеру слова в частотном списке. Например, если первое слово имеет частотность 60 000, то у второго слова будет частотность 60 000 / 2 = 30 000, у третьего — 60 000 / 3 = 20 000 и т. д. В реальном языке всё не получается так красиво: например, русский частотный словарь укладывался бы в закон Ципфа гораздо лучше, если бы у слова «и» частотность была не 35 802, а как раз около 60 000, тем не менее даже это приближение неплохо работает. Если изобразить распределение частот для первых 200 русских слов на графике, видно, что оно имеет форму гиперболы.
Закон Ципфа — один из редких примеров закона, который был открыт на материале языка, а потом нашел применение во множестве других областей.
Ему подчиняются размеры населенных пунктов, количество ссылок на сайты, размеры компаний: в стране обычно есть совсем немного крупных городов и много-много мелких населенных пунктов; есть небольшое количество очень важных сайтов, на которые все ссылаются, и много сайтов, на которые не ссылается никто или почти никто; бывают гигантские компании, но мелких гораздо больше.
Например, в Берлине 3,5 млн жителей; во втором по величине городе Германии — Гамбурге — примерно в два раза меньше: 1,8 млн. В шестом городе страны — Штутгарте — примерно в шесть раз меньше: 600 тысяч, и т. д. Видно, что на этих данных закон Ципфа работает превосходно.
Когда пытаются понять, написан ли какой-то текст на человеческом языке или нет, одна из первых проверок, которые стоит сделать, — посмотреть, подчиняется ли текст закону Ципфа.
Например, в загадочном манускрипте Войнича закон Ципфа соблюден довольно неплохо. Правда, это только необходимое условие, но еще не доказательство того, что перед нами естественный язык: именно потому, что закон Ципфа применим почти к чему угодно, в том числе и к неязыковым данным.
Зачем нужны частоты
Частотный словарь может быть полезен на практике для изучающих иностранный язык: конечно, не стоит заставлять человека, когда он узнает новое слово, выяснять точно, какое именно место в частотном списке оно занимает, но можно дать ему представление о том, стоит ли вообще это слово запоминать. Например, в словарях издательства Macmillan есть два типа слов: красные и чёрные, причём у красных слов стоят еще звездочки — одна, две или три. Вот несколько примеров:

Красные слова с тремя звездочками занимают в частотном словаре места с 1-го по 2500-е, слова с двумя звездочками — с 2501-го по 5000-е, а слова с одной звездочкой — с 5001-го по 7500-е. Черные слова располагаются ниже 7500-го места. Для пользователя это имеет очень простые следствия. Если ты ищешь в словаре слово и видишь при нем три звездочки, выучи его обязательно: оно наверняка попадется еще много раз. Если при слове только одна звездочка, это достаточно полезное слово, но часто не пригодится. И, наконец, черные слова — совсем редкие; их стоит заучивать, только если стремишься выучить язык на продвинутом уровне, но если не получится, то ничего страшного. Можно прекрасно говорить по-английски, не зная, что thatch значит «соломенная крыша», а crescent — «полумесяц»; без слов restriction «ограничение» и allegedly «якобы» тоже можно прожить, а вот слова animal «животное» и play «играть» точно надо знать.
Еще одна важная область, в которой применяется частотный анализ, — это автоматическая обработка текста (natural language processing). Например, для проверки орфографии и исправления опечаток очень важно понимать, какие слова редкие, а какие — частотные. Предположим, что пользователь напечатал такую английскую фразу:
I am looking at teh black dog.
Мы прекрасно понимаем, что в ней содержится опечатка: вместо teh должно быть написано the. Но ведь teh могло легко получиться и из чего-нибудь другого: что если пользователь хотел ввести ten, но случайно попал в букву h вместо n? Или, может быть, он хотел напечатать tech, но пропустил букву c? Почему же мы всё-таки полагаем, что имелось в виду слово the, в котором переставились две буквы? Можно, конечно, долго рассуждать о том, что с ten и с tech получится неправильное предложение (например, ten black dog — плохое сочетание слов, а должно быть ten black dogs), но это знание трудно формализовать и вложить в компьютер. Но можно поступить проще: заглянем в частотный словарь, и он сообщит нам, что the — самое популярное английское слово, так что вероятность того, что пользователь хотел напечатать именно его, особенно велика. Эта стратегия — всегда исправляй опечатку на самое частотное из похожих слов — может показаться примитивной, но она неплохо работает.
В 2007 году директор по исследованиям компании Google Питер Норвиг за несколько часов, проведе–нных в самолете (даже без интернета!), написал программу для исправления опечаток, которая занимает всего 22 строки кода на языке Python и в первую очередь опирается на частотность.
Всё это свидетельствует об одном: человеческий язык не описывается только грамматическими правилами. Важно знать, как часто встречаются в нем те или иные слова. К счастью, такие знания благодаря компьютерам можно очень легко получить, и это открывает для лингвистики новые перспективы.
Частотный словарь русского языка
Вторая версия частотного списка
На этой странице Вы можете получить списки наиболее частотных слов русского языка. До настоящего времени Частотный словарь русского языка под ред. Л.Н.Засориной (1977) чаще всего использовался в качестве источника информации о частоте русских слов. Однако корпус, на основе которого была подсчитана частота слов в этом словаре, по современным стандартам очень мал (около миллиона слов). Кроме того, список существенно устарел: он соответствует частоте использования слов в период с 20-х до 60-х годов. В результате корпус включает большое число идеологических источников, например, произведения Ленина и Калинина, Материалы 22 и 23 съездов КПСС, советские газеты. Слова советский и товарищ входят в первую сотню русских слов, наряду со служебными словами (они встречаются чаще слов где, здесь, ваш ), слова партия, революция, коммунистический встречаются чаще чем назад, около, лучше и т.д. Наконец, список слов из словаря Засориной не существует в электронном виде.
Список слов, доступный с этой страницы, содержит примерно 35000 слов с частотой большей 1 ipm (вхождений на миллион слов, instances per million words). Имеется также более короткий список из 5000 наиболее частотных русских слов. Списки используют кодировку кириллицы Windows-1251 и упакованы утилитой WinZip (пользователи Linux или Mac могут использовать StuffIt для распаковки).
Слова с частотой больше 1 ipm
Список 5000 наиболее частых слов
Некоторые статистические данные об использовании русских слов
Более полная информация о соответствии между частотой слова и покрытием корпуса находится здесь.
Список построен на основе представительного корпуса современного русского языка. Он включает в себя подборку современной прозы, политических мемуаров, современных газет и научно-популярной литературы (около 40 миллионов слов, проза составляет примерно чуть больше половины объема). Все тексты корпуса были написаны на русском в промежутке между 1970 и 2002; большинство между 1980 и 1995, газетный корпус 1997-1999 (корпус основан на текстах из Библиотеки Мошкова и корпуса современной публицистики А.В.Баранова).
Хорошо известно, что большие тексты представляют проблему для составления частотных списков, поскольке относительно длинный текст может содержать большое количество вхождений некоторого редкого слова, что существенно увеличит его частоту в итоговом списке. Например, корпус, использованный для составления данного списка, содержит вариацию на тему Толкиеновского «Повелителя Колец» (автор Ник Перумов). Несмотря на то, что длина этого романа составляет 250 тыс.слов, менее одного процента всего корпуса, частота использования слова хоббит в этом романе ставит его в первую тысячу русских слов, если частоту считать по всем текстам без ограничений на их длину. По этой причине частотные списки были составлены при условии, что выборка из больших текстов ограничена 10 тыс. слов, и выборка из текстов одного автора составляет менее 100 тыс. слов. В результате подмножество полного корпуса, использованное при подсчете частоты, составляет около 16 миллионов слов.
Корпус, средства для работы с ним, а также параллельный англо-русский корпус (выравнение на основе предложения) описаны, в частности, в следующей публикации автора:
Sharoff, Serge, (2002). Meaning as use: exploitation of aligned corpora for the contrastive study of lexical semantics. Proc. of Language Resources and Evaluation Conference (LREC02). May, 2002, Las Palmas, Spain. PDF file.
Также отдельные частотные списки есть для следующих классов слов:
Создание корпуса, разработка соответствующих программных средств и частотных списков были поддержаны грантом, предоставленным автору Фондом имени Гумбольдта, Германия. Лемматизация для анализа словоформ в корпусе была проведена с помощью морфологического анализатора Диалинг. Поскольку многие словоформы неоднозначны (например, дорогой, были, стали, для, три, уже ), частота некоторых слов не вполне достоверна, например, для рассматривалось как глагол, только если за ним не следует существительное, прилагательное или местоимение, стали всегда рассматривалось как существительное, для супруги всегда выбиралось супруга при возможных супруг и супруги (мн.ч). Критериями для выбора словоформы служили:
Частотный словарь русского языка для детей
До настоящего времени Частотный словарь русского языка под редакцией Л.Н.Засориной (1977) чаще всего использовался в качестве источника информации о частоте русских слов. Однако, использованный для словаря корпус, по современным стандартам, мал (примерно один миллион слов). Устарел и список слов, т.к. он соответствует частоте применения слов с 20-х до 60-х годов прошлого века. Корпус включает много идеологических источников: произведения Ленина и Калинина, материалы XXII и XXIII съездов КПСС, советские газеты. Слова советский и товарищ входят в первую сотню русских слов, наряду со служебными словами (они встречаются чаще слов где, здесь, ваш); слова партия, революция, коммунистический встречаются чаще, чем назад, около, лучше и т.д. Кроме того, список слов из словаря Засориной не существует в электронном виде.
Кроме того, существует более новое издание: Ольга Ляшевская, Сергей Шаров. Частотный словарь современного русского языка, 2009. 1112 с.
Этот частотный словарь содержит сведения о наиболее употребительных словах современного русского языка. Он создан на основе Национального корпуса русского языка, авторитетного и представительного электронного ресурса. Подкорпус 1950-2007 гг. объемом 92 млн. словоупотреблений включает тексты художественной литературы, средств массовой информации, технические, деловые документы и т.д., а также записи разговорной речи.
Словарь представляет разнообразную статистическую информацию для 50 тыс. слов общей лексики и 3 тыс. имен собственных и аббревиатур. Приводятся частотные списки лексики, характерной для публицистики, устной речи и других функциональных жанров, а также списки наиболее употребительных существительных, прилагательных, глаголов и слов других частей речи.
Заказать этот словарь можно в сетевом книжном магазине Озон.
Разделы страницы об частотном словаре Шарова:
Смотрите также библиографию по лексико-статистическим русским словарям.
Рубрикация Шаровского словаря
Для удобства словарь Сергея Шарова разделён на рубрики по сотне слов.
Статистика использования русских слов
Сетевые источники
Ссылки в сети на Шаровский частотный словарь:
Для чего нужны частотные словари и почему одни слова важнее других?
Компьютеры стали активно использоваться в лингвистике только в последней четверти XX века. До того ученые, которые изучали язык, по большей части занимались описанием грамматических правил и значений слов, не опираясь на количественные данные. Но когда появилась возможность обрабатывать большие массивы текстов, стало ясно, что мы многое теряем, если не различаем частотные и редкие явления. О том, какую пользу могут принести исследования частотности в языке, специально для «Ножа» рассказывает Александр Пиперски — доцент РГГУ, научный сотрудник НИУ ВШЭ, лауреат премии «Просветитель»–2017.
Заглонитель и турмы
Попробуйте прочитать такой текст на русском языке:
Заглонитель Ланс Оливер чуть не погиб в результате наплочения турма. Он ехал ласкунно на лошади покровнательно от Мэнсфилда (Австралия) и увидел вахню турмов, в которой было кастожно 15 животных. Столенно, ничего бы и не случилось, если бы собака Оливера не начала порочить на вахню.
Один из турмов — старый, крупный лователь, выбатушенный корочением собаки, бросился за ней. Та отпешила скумановаться за лошадью, на которой сидел Оливер. Тогда турм бросился уже на Оливера. Он схватил подвешенца отмаленными твинами за плечи и вытокнул его на землю.
Цитируется по: Р. М. Фрумкина. Психолингвистика. М., 2001
Вы встретили множество незнакомых слов, но нет сомнений, что вы в целом поняли, о чем здесь говорится, и даже можете пересказать содержание. А сконструирован этот текст очень простым способом: взят нормальный текст, но сохранены в нем только самые частотные слова, а все редкие заменены вымышленными. Вот оригинал этой истории:
Скотовод Ланс Оливер чуть не погиб в результате нападения кенгуру. Он ехал верхом на лошади неподалеку от Мэнсфилда (Австралия) и увидел стадо кенгуру, в котором было примерно 15 животных. Возможно, ничего бы и не случилось, если бы собака Оливера не начала лаять на стадо.
Один из кенгуру — старый крупный самец, раздраженный лаем собаки, бросился за ней. Та попыталась укрыться за лошадью, на которой сидел Оливер. Тогда кенгуру бросился уже на Оливера. Он схватил всадника передними лапами за плечи и сбросил его на землю.
Получается, для того, чтобы понимать человеческий язык, достаточно неполных знаний. Более того, полных знаний и не бывает: никто из нас не может знать все слова и гарантировать, что поймет от начала и до конца любое встретившееся ему предложение.
«и», «в», «не», «на»: частотный словарь
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке? Ну или не понимать, а хотя бы опознавать 20 % слов в тексте.
Очевидно, что полезно сперва учить частотные слова, а потом уже редкие: знать слово «собака» куда важнее, чем «самец» или «всадник», и уж тем более, чем «вольвокс» или «рейсфедер».
Самый популярный частотный словарь для русского языка в 2009 году создали Ольга Ляшевская и Сергей Шаров. Он свободно доступен на сайте Института русского языка им. В. В. Виноградова. Первое по частотности русское слово — это слово «и», за ним следуют «в», «не», «на», «я» и т. д. — вот и будем запоминать их подряд по этому списку:
Вернемся к предложению, в котором мы поставили перед собой задачу:
Представьте себе, что вы изучаете русский язык и хотите узнать: сколько слов надо выучить, чтобы понимать 20 % текста на этом языке?
В нем 20 слов, а значит, 20 % от них — это 4 слова. А теперь присмотритесь внимательно: оказывается, выучив первые 14 слов из частотного словаря, мы и узнаем в этом тексте 4 слова — «что», «и», «на» и «этом». Желанный результат достигнут: 20 % текста поняты (хотя до смысла, конечно, еще очень далеко).
В частотном словаре каждому слову приписано число, которое показывает, сколько раз это слово встретится, если мы возьмем текст длиной 1 миллион слов. Слово «и» мы в таком тексте увидим примерно 35 802 раза, слово «в» — 31 374 раза и т. д. Если сложить частоты первых 14 слов, то окажется, что они покроют 188 072 слова из миллиона — то есть почти те самые 20 %, к которым мы стремились. Чтобы выйти за 200 000, к ним надо добавить еще три слова («к», «но» и «они»). А чтобы понять 10 % текста, достаточно и вовсе 4 слов.
Вот полные списки слов, которых хватит, чтобы понять 10 %, 20 %, 30 % и 40 % текста на русском языке:
Видно, что на первые 10 % у иностранца уйдет совсем мало усилий. На следующие 10 % понадобится еще 13 слов; чтобы достигнуть 30-процентного понимания, придется добавить 29 слов, а чтобы добраться до 40 % — 86 слов. Чем дальше мы идем по частотному списку, тем менее полезно нам каждое следующее слово:
Иначе говоря, в любом языке есть совсем немного высокочастотных слов и много низкочастотных. Например, 1 раз на миллион слов, согласно словарю Ляшевской и Шарова, встретится 1478 слов; среди них — «резвость», «увильнуть», «боезапас», «сызнова», «картографирование». Ясно, что это совсем не то, что надо учить в первую очередь.
Слова, города и всё на свете: закон Ципфа
Частоты слов подчиняются простой математической закономерности, которую в середине XX века открыл американец Джордж Кингсли Ципф (1902–1950).
Источник
Он сформулировал такую зависимость, которая получила название «закон Ципфа»: частотность слова обратно пропорциональна номеру слова в частотном списке. Например, если первое слово имеет частотность 60 000, то у второго слова будет частотность 60 000 / 2 = 30 000, у третьего — 60 000 / 3 = 20 000 и т. д. В реальном языке всё не получается так красиво: например, русский частотный словарь укладывался бы в закон Ципфа гораздо лучше, если бы у слова «и» частотность была не 35 802, а как раз около 60 000, тем не менее даже это приближение неплохо работает. Если изобразить распределение частот для первых 200 русских слов на графике, видно, что оно имеет форму гиперболы.
Закон Ципфа — один из редких примеров закона, который был открыт на материале языка, а потом нашел применение во множестве других областей.
Ему подчиняются размеры населенных пунктов, количество ссылок на сайты, размеры компаний: в стране обычно есть совсем немного крупных городов и много-много мелких населенных пунктов; есть небольшое количество очень важных сайтов, на которые все ссылаются, и много сайтов, на которые не ссылается никто или почти никто; бывают гигантские компании, но мелких гораздо больше.
Например, в Берлине 3,5 млн жителей; во втором по величине городе Германии — Гамбурге — примерно в два раза меньше: 1,8 млн. В шестом городе страны — Штутгарте — примерно в шесть раз меньше: 600 тысяч, и т. д. Видно, что на этих данных закон Ципфа работает превосходно.
Когда пытаются понять, написан ли какой-то текст на человеческом языке или нет, одна из первых проверок, которые стоит сделать, — посмотреть, подчиняется ли текст закону Ципфа.
Например, в загадочном манускрипте Войнича закон Ципфа соблюден довольно неплохо. Правда, это только необходимое условие, но еще не доказательство того, что перед нами естественный язык: именно потому, что закон Ципфа применим почти к чему угодно, в том числе и к неязыковым данным.
Зачем нужны частоты
Частотный словарь может быть полезен на практике для изучающих иностранный язык: конечно, не стоит заставлять человека, когда он узнает новое слово, выяснять точно, какое именно место в частотном списке оно занимает, но можно дать ему представление о том, стоит ли вообще это слово запоминать. Например, в словарях издательства Macmillan есть два типа слов: красные и чёрные, причём у красных слов стоят еще звездочки — одна, две или три. Вот несколько примеров:
Красные слова с тремя звездочками занимают в частотном словаре места с 1-го по 2500-е, слова с двумя звездочками — с 2501-го по 5000-е, а слова с одной звездочкой — с 5001-го по 7500-е. Черные слова располагаются ниже 7500-го места. Для пользователя это имеет очень простые следствия. Если ты ищешь в словаре слово и видишь при нем три звездочки, выучи его обязательно: оно наверняка попадется еще много раз. Если при слове только одна звездочка, это достаточно полезное слово, но часто не пригодится. И, наконец, черные слова — совсем редкие; их стоит заучивать, только если стремишься выучить язык на продвинутом уровне, но если не получится, то ничего страшного. Можно прекрасно говорить по-английски, не зная, что thatch значит «соломенная крыша», а crescent — «полумесяц»; без слов restriction «ограничение» и allegedly «якобы» тоже можно прожить, а вот слова animal «животное» и play «играть» точно надо знать.
Еще одна важная область, в которой применяется частотный анализ, — это автоматическая обработка текста (natural language processing). Например, для проверки орфографии и исправления опечаток очень важно понимать, какие слова редкие, а какие — частотные. Предположим, что пользователь напечатал такую английскую фразу:
I am looking at teh black dog.
Мы прекрасно понимаем, что в ней содержится опечатка: вместо teh должно быть написано the. Но ведь teh могло легко получиться и из чего-нибудь другого: что если пользователь хотел ввести ten, но случайно попал в букву h вместо n? Или, может быть, он хотел напечатать tech, но пропустил букву c? Почему же мы всё-таки полагаем, что имелось в виду слово the, в котором переставились две буквы? Можно, конечно, долго рассуждать о том, что с ten и с tech получится неправильное предложение (например, ten black dog — плохое сочетание слов, а должно быть ten black dogs), но это знание трудно формализовать и вложить в компьютер. Но можно поступить проще: заглянем в частотный словарь, и он сообщит нам, что the — самое популярное английское слово, так что вероятность того, что пользователь хотел напечатать именно его, особенно велика. Эта стратегия — всегда исправляй опечатку на самое частотное из похожих слов — может показаться примитивной, но она неплохо работает.
В 2007 году директор по исследованиям компании Google Питер Норвиг за несколько часов, проведе–нных в самолете (даже без интернета!), написал программу для исправления опечаток, которая занимает всего 22 строки кода на языке Python и в первую очередь опирается на частотность.
Всё это свидетельствует об одном: человеческий язык не описывается только грамматическими правилами. Важно знать, как часто встречаются в нем те или иные слова. К счастью, такие знания благодаря компьютерам можно очень легко получить, и это открывает для лингвистики новые перспективы.
Списки частотных слов русского языка
Список самых частотных слов любого языка зависит от того материала, на котором эта частота считалась. В данном случае был использован Национальный корпус русского языка. Кроме того, списки, приведённые ниже, предполагают лемматизацию, то есть приведение всех словоформ к их словарной форме, например, все формы были, буду, бывший приведены к форме быть, что в последнем случае может оспариваться некоторыми лингвистами.
Частоты приведены к чмс (частота на миллион словоформ, ipm, instances per million words), что означает, что слово Москва в среднем встречается 452 раза на один миллион слов текста (на основе материалов НКРЯ). В результате лемматизации все слова приведены к нижнему регистру, включая слова, которые в большинстве случаев пишутся с большой буквы.
Три колонки: существительные, глаголы, прилагательные.
| Частота | Слово |
|---|---|
| 2369 | человек |
| 1529 | время |
| 1490 | год |
| 1195 | дело |
| 1119 | жизнь |
| 1024 | рука |
| 1005 | день |
| 839 | слово |
| 835 | раз |
| 747 | глаз |
| 743 | лицо |
| 724 | место |
| 670 | дом |
| 660 | работа |
| 658 | Россия |
| 624 | друг |
| 622 | сторона |
| 611 | голова |
| 590 | вопрос |
| 550 | сила |
| 543 | мир |
| 529 | случай |
| 503 | ребенок |
| 472 | город |
| 468 | вид |
| 463 | страна |
| 453 | конец |
| 452 | Москва |
| 449 | бог |
| 442 | часть |
| Частота | Слово |
|---|---|
| 8900 | быть |
| 2398 | мочь |
| 2053 | сказать |
| 1492 | говорить |
| 1427 | знать |
| 1291 | есть |
| 1186 | стать |
| 849 | хотеть |
| 793 | иметь |
| 758 | видеть |
| 711 | идти |
| 669 | думать |
| 608 | жить |
| 602 | сделать |
| 561 | делать |
| 505 | пойти |
| 496 | дать |
| 465 | взять |
| 455 | смотреть |
| 453 | спросить |
| 451 | любить |
| 439 | понимать |
| 434 | сидеть |
| 402 | казаться |
| 391 | работать |
| 382 | стоить |
| 381 | прийти |
| 380 | понять |
| 368 | выйти |
| 359 | давать |
| Частота | Слово |
|---|---|
| 876 | новый |
| 554 | последний |
| 473 | русский |
| 456 | хороший |
| 429 | большой |
| 373 | высокий |
| 362 | российский |
| 339 | молодой |
| 339 | великий |
| 326 | старый |
| 317 | главный |
| 312 | общий |
| 308 | маленький |
| 303 | полный |
| 266 | настоящий |
| 265 | разный |
| 263 | белый |
| 258 | государственный |
| 241 | далекий |
| 237 | черный |
| 231 | нужный |
| 226 | известный |
| 224 | советский |
| 223 | целый |
| 213 | живой |
| 210 | сильный |
| 209 | военный |
См. также
Литература
Смотреть что такое «Списки частотных слов русского языка» в других словарях:
Самое длинное слово русского языка — Решение проблемы того, какое слово в русском языке является самым длинным (и даже ответ на вопрос о том, имеет ли вообще эта проблема решение), зависит от нескольких факторов. Содержание 1 Критерии 2 Условия выбора 2.1 Форма слов … Википедия
Национальный корпус русского языка — URL: http://ruscorpora.ru/ Коммерческий: нет Тип сайта: образовательный/научный проект Реги … Википедия
Частотный словарь — (или частотный список) набор слов данного языка (или подъязыка) вместе с информацией о частоте их встречаемости. Словарь может быть отсортирован по частоте, по алфавиту (тогда для каждого слова будет указана его частота), по группам слов… … Википедия
Русский язык — У этого термина существуют и другие значения, см. Русский язык (значения). Русский язык Произношение: ˈruskʲɪj jɪˈzɨk … Википедия
Частотность — термин лексикостатистики, предназначенный для определения наиболее употребительных слов. Расчёт осуществляется по формуле: где Freqx частотность слова «x», Qx количество словоупотреблений слова «x», Qall общее количество словоупотреблений. В… … Википедия
НКРЯ — Национальный корпус русского языка общедоступный для поиска электронный онлайновый корпус русских текстов. Открыт 29 апреля 2004 в Интернете по адресу http://ruscorpora.ru/. Содержание 1 Составители 2 Состав корпуса … Википедия
словарь лингвистический — Словарь, в котором дается разъяснение значения и употребления слов (в отличие от энциклопедического словаря, сообщающего сведения о соответствующих реалиях предметах, явлениях, событиях). Диалектный (областной) словарь. Словарь, содержащий… … Словарь лингвистических терминов
Медицина — I Медицина Медицина система научных знаний и практической деятельности, целями которой являются укрепление и сохранение здоровья, продление жизни людей, предупреждение и лечение болезней человека. Для выполнения этих задач М. изучает строение и… … Медицинская энциклопедия
Частотный словарь русского языка для детей
Вторая версия частотного списка
На этой странице Вы можете получить списки наиболее частотных слов русского языка. До настоящего времени Частотный словарь русского языка под ред. Л.Н.Засориной (1977) чаще всего использовался в качестве источника информации о частоте русских слов. Однако корпус, на основе которого была подсчитана частота слов в этом словаре, по современным стандартам очень мал (около миллиона слов). Кроме того, список существенно устарел: он соответствует частоте использования слов в период с 20-х до 60-х годов. В результате корпус включает большое число идеологических источников, например, произведения Ленина и Калинина, Материалы 22 и 23 съездов КПСС, советские газеты. Слова советский и товарищ входят в первую сотню русских слов, наряду со служебными словами (они встречаются чаще слов где, здесь, ваш), слова партия, революция, коммунистический встречаются чаще чем назад, около, лучше и т.д. Наконец, список слов из словаря Засориной не существует в электронном виде.
Список слов, доступный с этой страницы, содержит примерно 35000 слов с частотой большей 1 ipm (вхождений на миллион слов, instances per million words). Имеется также более короткий список из 5000 наиболее частотных русских слов. Списки используют кодировку кириллицы utf8 и упакованы утилитой WinZip (пользователи Linux или Mac могут использовать StuffIt для распаковки).
Более полная информация о соответствии между частотой слова и покрытием корпуса находится здесь.
Список построен на основе представительного корпуса современного русского языка. Он включает в себя подборку современной прозы, политических мемуаров, современных газет и научно-популярной литературы (около 40 миллионов слов, проза составляет примерно чуть больше половины объема). Все тексты корпуса были написаны на русском в промежутке между 1970 и 2002; большинство между 1980 и 1995, газетный корпус 1997-1999 (корпус основан на текстах из Библиотеки Мошкова и корпуса современной публицистики А.В.Баранова).
Хорошо известно, что большие тексты представляют проблему для составления частотных списков, поскольке относительно длинный текст может содержать большое количество вхождений некоторого редкого слова, что существенно увеличит его частоту в итоговом списке. Например, корпус, использованный для составления данного списка, содержит вариацию на тему Толкиеновского «Повелителя Колец» (автор Ник Перумов). Несмотря на то, что длина этого романа составляет 250 тыс.слов, менее одного процента всего корпуса, частота использования слова хоббит в этом романе ставит его в первую тысячу русских слов, если частоту считать по всем текстам без ограничений на их длину. По этой причине частотные списки были составлены при условии, что выборка из больших текстов ограничена 10 тыс. слов, и выборка из текстов одного автора составляет менее 100 тыс. слов. В результате подмножество полного корпуса, использованное при подсчете частоты, составляет около 16 миллионов слов.
Распределение слов в текстах далеко от равномерного. Некоторые слова (например, предлоги) встречаются во многих текстах с вполне предсказуемой частотой. Частота других (например, местоимений или ментальных глаголов) существенно зависит от автора или жанра текста, в то время как многие слова относятся к «заразным»: если это слово (например, имя собственное, обозначение человека по званию или должности или технический термин) встретилось в тексте один раз, весьма вероятно, что оно повторится там еще много раз, таким образом, существенно повышая его частоту в документе. Сушествуют разные способы измерения такой вариации (Church, K. and Gale, W. (1995) Poisson Mixtures, Journal of Natural Language Engineering, 1:2). Простейший способ для оценки поведения слова: посчитать коэффициент вариации, который вычисляется как среднеквадратичное отклонение, поделенное на среднее значение. Среднеквадратичное отклонение дает абсолютное значение вариации набора данных (оно увеличивается для слов с большей средней частотой), в то время как коэффициент вариации позволяет сравнить распределение слов с неравной средней частотой. Значения отклонений для 5000 наиболее частотных слов можно посмотреть здесь. Структура файла:
лемма, средняя частота (ipm), число текстов, в которых это слово встречается, среднеквадратичное отклонение частоты по все текстам, коэффициент вариации, дисперсия.
Корпус, средства для работы с ним, а также параллельный англо-русский корпус (выравнение на основе предложения) описаны, в частности, в следующей публикации автора:
Sharoff, Serge, (2002). Meaning as use: exploitation of aligned corpora for the contrastive study of lexical semantics. Proc. of Language Resources and Evaluation Conference (LREC02). May, 2002, Las Palmas, Spain. PDF file.