

С этим понятием вы не раз встречались в жизни, если вам приходилось работать с текстами. В частности, вы могли обращаться к онлайн-калькуляторам, осуществляющим именно частотный анализ текста. Эти удобные инструменты показывают, сколько раз тот или иной символ или буква встречались в каком-либо отрывке текста. Нередко показывается и процентное соотношение. Зачем это нужно? Как частотный анализ текста способствует «взлому» простых шифров? В чем его суть, кто его изобрел? На эти и другие важные вопросы по теме мы ответим по ходу статьи.
- Определение
- Характеристка процесса
- История метода
- Основа метода
- Часто встречающиеся буквы русского алфавита
- Би-, три-, четырехграммы
- Предпочтительные связи букв друг с другом
- Что определяет анализ?
- Борьба с переоптимизацией и перенасыщенностью
- Помощь частнотного анализа СЕО-специалистам
- Проверяемые безударные гласные в корне слова
- Ударение и проверяемые безударные гласные
- Правило
- Способы проверки безударных гласных в корне
- Примеры слов с проверяемыми безударными гласными
- Видеоурок для 3 класса «Правописание безударных гласных в корне слов»
- Какие слова пишутся с заглавной буквы
- Прописные и строчные буквы — что это такое?
- Употребление прописных и строчных букв
- Правила написания прописных букв в именах собственных
- Что ещё пишется с большой буквы
Определение
Частотный анализ выступает одной из разновидностей криптоанализа. Он основывается на предположении ученых о существовании статистического нетривиального распределения отдельных символов и их закономерных последовательностей как в открытом, так и шифрованном видах текста.
Считается, что подобное распределение с точностью до замены отдельных символов будет сохраняться также в процессах шифрования/дешифрования.

Характеристка процесса
Разберем теперь частотный анализ простым языком. Здесь подразумевается, что количество появлений одного и того же символа алфавита в текстах достаточной длины одно и то же в различных текстах, написанных на одном и том же языке.
И что теперь с моноалфавитным шифрованием? Предполагается, что если в участке с шифрованным текстом будет символ с такой аналогичной вероятностью появления, то реально предположить, что именно он и есть та зашифрованная буква.
Такие же рассуждения последователи частотного анализа текста применяют и по отношении к биграммам (последовательностям из двух букв). Триграммам — это для случая уже полиалфавитных шифров.
История метода
Частотный анализ слов не является находкой современности. Научному миру он известен еще с IX века. Его создание связывают с именем Ал-Кинди.
Но известные случаи применения метода частотного анализа относятся к гораздо более позднему периоду. Самым ярким примером здесь можно назвать дешифровку египетских иероглифов, произведенную в 1822 году Ж.-Ф. Шампольоном.
Если мы обратимся к художественной литературе, то можем найти немало любопытных отсылов к подобному методу дешифровки:
- Конан Дойль — «Плящущие человечки».
- Жюль Верн — «Дети капитана Гранта».
- Эдгар По — «Золотой жук».
Однако начиная с середины прошлого века большинство используемых алгоритмов в шифровании разрабатывается с учетом их устойчивости к подобному частотному криптоанализу. Поэтому его сегодня применяют чаще всего лишь для обучения будущих криптографов.

Основа метода
Представим теперь анализ частотных характеристик детально. Эта разновидность анализа прямо базируется на том, что тест состоит из слов, а те, в свою очередь, из букв. Количество букв, наполняющих национальные алфавиты, ограничено. Буквы могут быть тут просто перечислены.
Важнейшими характеристиками подобного текста будет как повторяемость букв, различных биграмм, триграмм и n-грамм, так и сочетаемость различных букв друг с другом, чередование согласных/гласных и других разновидностей данных символов.
Главная идея методов — в подсчете вхождений из возможных n-грамм (обозначается nm) в достаточно длинных для анализа открытых текстах (обозначаются T=t1t2…tl), составленных из букв национального алфавита (обозначаются ). Все вышеперечисленное обуславливает некоторые идущие подряд m-граммы текста:
t1t2. tm, t2t3. tm+1, . ti-m+1tl-m+2. tl.
Если это – количество появлений m-граммы ai1ai2. aim в определенном тексте T, а L – общее число проанализированных исследователем m-грамм, то опытным путем возможно установить, что при достаточно больших L частоты для такой m-граммы будут мало чем отличаться друг от друга.

Часто встречающиеся буквы русского алфавита
А вот частотно-временной анализ, несмотря на похожее название, к теме нашего разговора никакого отношения не имеет. Такого рода анализ осуществляется в отношении сигналов малозаметных радиолокационных станций при помощи специального вейвлет-преобразования.
Вернемся теперь к главной теме. При проведении частотного анализа можно выяснить, какие буквы русского алфавита встречаются в достаточно объемных текстах чаще всего (процентное отношение от 0,062 до 0,018):
- А.
- В.
- Д.
- Ж.
- И.
- К.
- М.
- О.
- Р.
- Т.
- Ф.
- Ц.
- Ш.
- Ь.
- Э.
- Я.
Введено даже специальное мнемоническое правило, которое помогает усвоить самые распространенные буквы русского алфавита. Для этого достаточно запомнить всего одно слово — «сеновалитр».
В общих случаях частота использования букв в процентном выражении устанавливается просто: специалист подсчитывает, сколько раз буква встречается в тексте, затем делит получившееся значение на общее количество символов в тексте. А для выражения данной величины в процентах достаточно умножить ее на 100.
Важно учитывать, что частотность будет зависит не только от объема текста, но также и от его характера. К примеру, в технических источниках буква «Ф» фигурирует гораздо чаще, нежели в художественных. Поэтому для объективных результатов специалист должен набирать для исследования тексты различного характера и стилистики.
Би-, три-, четырехграммы
В осмысленных текстах также можно встретить самые распространенные (соответственно, самые повторяющиеся) сочетания из двух и более букв. Специалистами составлено и несколько таблиц, где указаны частоты подобных биграмм разнообразных алфавитов.
Что касается русского, то частотный анализ систем объемных осмысленных текстов позволил установить самые распространенные биграммы и триграммы:
- ЕН.
- СТ.
- НО.
- НИ.
- НА.
- РА.
- ОВ.
- КО.
- ВО.
- СТО.
- НОВ.
- ЕНО.
- ТОВ.
- ОВА.
- ОВО.
Предпочтительные связи букв друг с другом
И это еще не все возможности, которые может предоставить частотный анализ исследователям текста. Систематизировав информацию из подобных таблиц биграмм и триграмм, реально извлечь данные о самых распространенных сочетаниях букв. Или, другими словами, их предпочтительных связях между собой.
Такое обширное исследование уже было проведено специалистами. Его результатом стала таблица, где вместе с каждой буквой алфавита были указаны ее соседи. Притом те символы, которые часто встречаются как непосредственно перед ней, так и после нее. Буквы в таблице прописаны не случайно. Ближе к символу обозначены самые частые соседи, дальше — более редкие.
- Буква «А». Тут выделяются следующие предпочтительные связи: л-д-к-т-в-р-н-А-л-н-с-т-р-в-к-м. Отсюда мы видим, что чаще всего перед «А» в текстах идет «Н» («НА»). А после «А» чаще всего в текстах на русском языке мы можем встретить «Л» («АЛ»).
- Буква «М». Специалисты выделили такие предпочтительные связи: «я-ы-а-и-е-о-М-и-е-о-у-а-н-п-ы».
- Буква «Ь». Предпочтительные связи следующие: «н-с-т-л-Ь-н-к-в-п-с-е-о-и».
- Буква «Щ». Предпочтительные связи: «е-б-а-я-ю-Щ-е-и-а».
- Буква «П». Предпочтительные связи с данным символом русского алфавита: «в-с-у-а-и-е-о-П-о-р-е-а-у-и-л».

Что определяет анализ?
Современные программы частотного анализа текста помогают изучить большие объемы самых разнообразных статей, сочинений, отрывков и проч. Исследователю стандартно предоставляется следующая информация:
- Общее количество символов в тексте.
- Число использованных автором пробелов.
- Количество цифр.
- Информация об использованных знаках препинания — точках, запятых и проч.
- Количество букв каждого из имеющихся алфавитов — кириллицы, латиницы и проч.
- Информация о частоте использования каждой буквы и символа в тексте — количество упоминаний и процентная величина в сравнении со всем текстом.
Борьба с переоптимизацией и перенасыщенностью
Зачем проводится частотный анализ текста? Только ли с целью любопытства — установить, какие символы в написанном тексте оказались часто встречаемыми? Нет, главное применение анализа — практическое, и оно заключается в другом.
К N-граммам относятся не только устойчивые биграммы и триграммы. К этой же категории можно отнести ключевые слова (теги), коллокации. То есть устойчивые сочетания, состоящие из двух и более слов. Их отличает факт, что такие композиции встречаются в тексте вместе и при этом несут определенную смысловую нагрузку.
Это на руку недобросовестным СЕО-специалистам. В своей работе они порой злоупотребляют повторением в тексте тегов, ключевых слов, чтобы искусственно повысить релевантность той или иной интернет-страницы. Они стараются обмануть систему и таким «фокусом»: превращая естественное сочетание с обычным, традиционным для русского языка сочетанием слов («купить норковую шубу») в несогласованное. То есть, полученное перестановкой слов в такой естественной N-грамме («шубу норковую купить»).
Но сегодня поисковые алгоритмы научились определять переоптимизацию так же эффективно, как и переспам — перенасыщенность текста ключевыми словами, тегами, влияющими на ранжирование результатов на странице поиска. Чрезмерно оптимизированные страницы теперь, напротив, получают более низкое положение по запросу пользователя. Да и сами люди не стремятся читать бессмысленный, перенасыщенный тегами текст, предпочитая ему полезную информацию на другом ресурсе.

Помощь частнотного анализа СЕО-специалистам
Таким образом, современные текстовые фильтры поисковиков отдают сегодня предпочтение тем интернет-страницам, информация на которых не только удобно читаема, но и полезна посетителям. Чтобы оптимизировать свою работу под новые стандарты, СЕО-специалисты и обращаются к частотному анализу текста. Его предоставляют сегодня многие популярные сервисы.
Частотный анализ помогает пересмотреть готовящийся к публикации текст на информативность. Исключить ненужную избыточность тегов и ключевых фраз. Позволяет также обратить внимание автора и на неестественные сочетания слов, которые вызывают подозрение у текстовых фильтров поисковых систем.

Частотный анализ текста, таким образом, помогает определить частоту упоминания того или иного символа в источнике. Метод сегодня применяется для оценки перенасыщенности текста тегами, неестественными перестановками слов.
Проверяемые безударные гласные в корне слова
Проверяемые безударные гласные в корне слова — это гласные, которые проверяют ударением с помощью подбора родственных слов или изменением грамматической формы слова.
Безударные гласные в корне слова могут быть проверяемыми и непроверяемыми. Выясним, что такое проверяемые безударные гласные, какими способами можно узнать, какую букву следует правильно написать в корне слова.
Ударение и проверяемые безударные гласные
Разберемся, в корне каких слов имеются проверяемые безударные гласные. При произношении слов голосом выделяется один гласный звук, а все остальные гласные оказываются в слабой фонетической позиции — без ударения:
- с о ло́ма
- укр а ше́ние
- при́г о р о дный
В русском языке ударение в словах является разноместным. Ударным может быть гласный любой морфемы:
1. приставки
- на́д п и сь
- о́т св е т
- вы́ л и нять
2. суффикса
- отп и л и́ ть
- св е ж о́
- уд и вл е́ ние
3. окончания
- з о л о т о́й
- тр а в а́
- м о рск о́й
Во всех указанных словах без ударения остались гласные корня, которые слышатся неясно. По этой причине возникает сомнение в выборе букв «о» или «а», «е» или «и». Во многих словах русского языка безударные гласные проверяются ударением.

Чтобы правильно написать слова с проверяемыми безударными гласными в корне, воспользуемся орфографическим правилом.
Правило
Способы проверки безударных гласных в корне
| Подобрать другую форму этого же слова | Подобрать родственные слова |
|---|---|
| 1. Один — много в о лна — в о́ лны | 1. Большой — маленький к о вёр — к о́ врик |
| 2. Много — один п а руса — п а́ рус | 2. Маленький — большой пл о щадка — пл о́ щадь |
| 3. По вопросу: Где? м о ря — в м о́ ре Что делал? Что делает? п и сал — п и́ шет | 3. Назови ласково з и ма — з и́ мушка |
| 4. Какой? — Что? з е лёный — з е́ лень | |
| 5. Что делал? — Что? пл я сал — пл я́ ска |
Понаблюдаем, как ударением можно проверить безударные гласные в корне с помощью подобранных родственных слов:
- вх о д и́ть — вход ;
- х и тр е́ц — хи́тр ый, хи́тр ость;
- раз д е л и́ть — раз де́л ;
- загад а́ть — зага́д ка, зага́д очный.
Изменим грамматическую форму слов, чтобы убедиться в написании проверяемых безударных гласных в корне:
- нак о рми́ть — нако́рмит;
- хв а ли́ть — хва́лит;
- н о га́ — но́ги;
- зал и за́ть рану — ли́жет.
Приведём примеры слов с безударными проверяемыми гласными, обозначенными буквами «а», «о», «е», «и», «я».
Примеры слов с проверяемыми безударными гласными
1. Буква «а» пишется в корне слов с проверяемой безударной гласной:
- гл а за́ — глаз, гла́зик;
- ч а стота́ — ча́стый;
- нак а ли́ть — накал;
- исп а ре́ние — пар;
- сокр а ти́ть — кра́ткий;
- пл а ти́ть — опла́та, пла́тный;
- ок а ти́лась водой из ведра — ка́тит;
- ш а ловли́вый — ша́лость;
- н а чала́ — на́чал.
2. Букву «о» в корне слов проверим ударением:
- нак о ли́ бабочку — ко́лет;
- погл о ща́ть — гло́тка;
- угр о жа́ть — угро́за;
- ум о лять — мо́лит;
- вышк о ли́ть — шко́ла;
- т о пта́ть — то́пчет;
- оп о здать — по́здно;
- уг о мони́ть — го́мон.
3. Докажем написание буквы «е» в корне слов с проверяемыми безударными гласными:
- нав е ва́ть раздумья — ве́ять;
- об е жа́ть дом — бег;
- вп е рёд — спе́реди;
- прор е ди́ть посевы — ре́дкий;
- пот е ря́ть — поте́ря;
- с е рьга́ — се́рьги;
- осв е ще́ние — свет.
В некоторых словах в написании буквы «е» в корне слова необходимо учитывать чередование е//ё. Если в корне проверочного слова пишется буква «ё», то в безударном положении выберем букву «е»:
- п е строта́ — пёстрый;
- в е сна́ — вёсны;
- по́ч е рк — зачёркнутый;
- подв е сти́ — подвёл.
4. Буква «и» пишется в корне слов:
- об и жа́ть малыша — оби́да;
- прим и ри́ть недругов — мир, переми́рие;
- прож и ва́ть в доме — жить;
- ч и стота́ в кухне — чи́стый;
- сп и са́ть слова — пи́шет;
- ед и не́ние — еди́нство.
5. Проверим букву «я»:
- разр я ди́ть ружьё — разря́д;
- прист я жна́я лошадь — пристя́жка;
- исс я ка́ть — исся́кнуть;
- посв я тить поэму — свя́тость;
- м я чи́ — мяч;
- ув я да́ть от жары — вя́лый.
Видеоурок для 3 класса «Правописание безударных гласных в корне слов»
Какие слова пишутся с заглавной буквы

Русский язык является одним из сложнейших языков мира, но особую сложность представляет раздел орфографии. Какие слова пишутся с заглавной буквы?
Чтобы не возникла путаница в этом вопросе, следует руководствоваться определёнными правилами. Рассмотрим детально данный вопрос.
Прописные и строчные буквы — что это такое?
Каждый школьник или студент сталкивался с понятиями прописная и строчная буква. В бытовой речи их принято называть большой и маленькой буквами. Несмотря на допустимые употребления в разговорной речи, русский язык имеет определённую терминологию и структуру написания азбучных знаков.
Главное отличие прописного символа от строчного является размер. Прописная буква именно та, с которой начинается новое предложение или мысль. Её принято также называть заглавной.
Пример. День был пасмурный. Буква «Д» заглавная, прописная, большая.
Строчный символ продолжает предложение и меньше заглавного.
Пример: был пасмурный. Буква «б» строчная, маленькая.
Употребление прописных и строчных букв
Существует ряд правил, когда необходимо использовать тот или иной буквенный знак. Знание данных норм употребления избавит от ошибок в написании. Разберем конкретные случаи, когда пишется прописная или строчная буква.
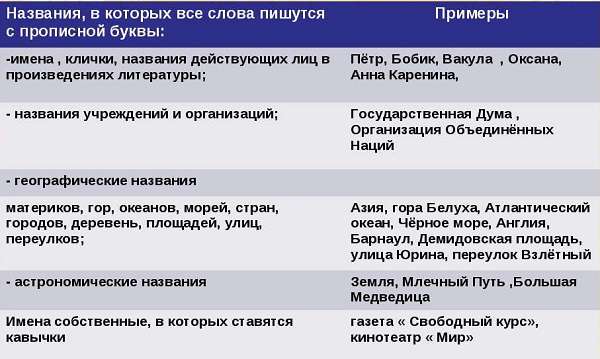
Итак, заглавная буква употребляется всегда:
- в начале предложения, абзаца или конкретной смысловой части,
- в прямой речи. Важно, что при этом используются кавычки,
- в начале цитаты,
- после следующих знаков препинания: точка, восклицательный и вопросительный знак, многоточие (если мысль закончена),
- в каждой новой строке стиха, независимо от знаков препинания,
- при написании прозвищ, псевдонимов, имён, фамилий и отчеств,
- в наименовании районов и областей (Подмосковье, Московская область),
- в названии марок, брендов,
- при описании исторически важных событий, а также территориально-административных пунктов (Европа, Сибирь, Север),
- в названии планет, их спутников, рек, морей, озёр и океанов (Луна, Солнце, Земля),
- при употреблении притяжательных имён собственных в родительном падеже (Олин мяч),
Все понятия, употребляющиеся только в контексте официальности, законодательных актов и состава государства начинаются с прописной буквы.
Примеры: Министерство Культуры, Российская Федерация, Федеральный закон, Администрация президента, московский Кремль, Конституция, Советская власть, Устав президента, Гражданская война, Постановление, Правительство, Управление.
Строчные (или маленькие) буквы пишутся в следующих случаях:
- в конце предложения или после первого и последующих слов,
- после запятой и точки с запятой,
- двоеточия (если далее не идёт прямая речь) и многоточия (если мысль не закончена),
- при наименовании различных чинов,
- в названиях месяцев.
Слова, характеризующие родовую принадлежность, а также не относящиеся к делам государственной важности, употребляются с маленькой буквы.
Примеры: кызы, оглы, российский сыр, московский, мир, всероссийский, государственный, россияне, москвичи, столица, университет, земля и т. д.
Правила написания прописных букв в именах собственных
Понятие имени собственного можно объединить в следующую группу:
- Личные данные: отчества, фамилии, имена.
- Клички животных.
- Прозвища, а также герои художественных книг.
- Астрономические и астрологические обозначения.
- Географические наименования.
- Бренды печатных изданий, автомобилей и табачных изделий.

Важно: главным отличием имён собственных от нарицательных является отсутствие множественного числа при их употреблении. Например: Евгений Онегин, газета « Ведомости».
Зачастую имена собственные могут переходить в разряд нарицательных. Например: Михаил Булгаков — имя собственное. Произведение написано булгаковским стилем — имя нарицательное. В таком случае прилагательное пишется со строчной буквы.
Что ещё пишется с большой буквы
Сложные существительные могут содержать прописные буквенные символы в середине слова, например: МосТорг.

Все слова, обозначающие высшие религиозные должностные лица, пишутся с заглавной буквы: Патриарх Кирилл, Папа Римский.
Все аббревиатуры имеют следующее написание: КПСС, СГУ, СПбГУ.
Написание местоимений может варьироваться в зависимости от смысла. Например, если обращение осуществляется в уважительной форме к одному лицу, то употребляется Вы, Вас, Вашей, Вашего. В случае множественного числа пишется вы, вас, вашей, вашего.
Есть слова, которые вызывают затруднение в графическом изображении. Например, существительное «республика» печатается с маленькой буквы, если оно употребляется отдельно от названия государства. Если входит в государственный состав, то печатаем «Республика Татарстан».
Заголовки и подзаголовки в текстах необходимо печатать с большой буквы. Заголовок, состоящий из всех заглавных букв — грубейшая ошибка.
Каждый год русский язык претерпевает изменения норм употребления, в том числе орфографических. Факт обусловлен появлением неологизмов и заимствований из иностранных языков.
Фундаментальные правила остаются неизменными. Метаморфозу претерпевают относительно молодые языковые единицы языка.