
Пусть, дано предложение “Съешьте еще этих мягких французских булок, да выпейте чаю.”, в котором нам нужно определить часть речи для каждого слова:
[(‘съешьте’, ‘глаг.’), (‘еще’, ‘нареч.’), (‘этих’, ‘местоим. прил.’), (‘мягких’, ‘прил.’), (‘французских’, ‘прил.’), (‘булок’, ‘сущ.’), (‘да’, ‘союз’), (‘выпейте’, ‘глаг.’), (‘чаю’, ‘сущ.’)]
Зачем это нужно? Например, для автоматического определения тегов для блог-поста (для отбора существительных). Морфологическая разметка является одним из первых этапов компьютерного анализа текста.
- Существующие решения
- Алгоритм
- Данные
- Реализация
- Тестирование
- Заключение и планы на будущее
- 10 сервисов, которые быстро посчитают количество символов в тексте
- 1. Text
- 2. Advego
- 3. Word
- 4. Simvoli.net
- 5. VIP-контент
- 6. Google Документы
- 7. Excel
- 8. Seostop
- 9. Copywritely
- 10. Slogi
- Сколько на одной странице букв, символов, слов?
- Заключение
- Семантический анализ текста istio
- Что показывает семантический анализ текста?
- Проверка тошноты статьи
- Водность текста
- Количество символов, частотность слов
Существующие решения
Конечно, все уже придумано до нас. Существует mystem от Яндекса, TreeTagger с поддержкой русского языка, на питоне есть nltk, а также pymorphy от kmike. Все эти утилиты отлично работают, правда, у pymorphy нет поддержки питона 3, а у nltk поддержка третей версии питона только в бете (и там вечно что-то отваливается). Но реальная цель для создания модуля — академическая, понять как работает морфологический анализатор.
Алгоритм
- Обычно мы знаем к какой части речи относится знакомое нам слово. Например, мы знаем, что “съешьте” — это глагол.
- Если нам встречается слово, которое мы не знаем, то мы можем угадать часть речи, сравнивая с уже знакомыми словами. Например, мы можем догадаться, что слово “конгруэнтность” — это существительное, т.е. имеет окончание “-ость”, присущее обычно существительным.
- Мы также можем догадаться какая это часть речи, проследив за цепочкой слов в предложении: “съешьте французских x” — в этом примере, х скорее всего будет существительным.
- Длина слова также может дать полезную информацию. Если слово состоит всего лишь из одной или двух букв, то скорее всего это предлог, местоимение или союз.
Данные
Для обучения нашего скрипта я использовал национальный корпус русского языка. Часть корпуса, СинТагРус, представляет собой коллекцию текстов с размеченной информацией для каждого слова, такой как, часть речи, число, падеж, время глагола и т.д. Так выглядит часть корпуса в XML формате:
Предложения заключены в теги <se>, внутри которых расположены слова в теге <w>. Информация о каждом слове содержится в теге <ana>, аттрибут lex соответствует лексеме, gr — грамматические категории. Первая категория — это часть речи:
‘S’: ‘сущ.’,
‘A’: ‘прил.’,
‘NUM’: ‘числ.’,
‘A-NUM’: ‘числ.-прил.’,
‘V’: ‘глаг.’,
‘ADV’: ‘нареч.’,
‘PRAEDIC’: ‘предикатив’,
‘PARENTH’: ‘вводное’,
‘S-PRO’: ‘местоим. сущ.’,
‘A-PRO’: ‘местоим. прил.’,
‘ADV-PRO’: ‘местоим. нареч.’,
‘PRAEDIC-PRO’: ‘местоим. предик.’,
‘PR’: ‘предлог’,
‘CONJ’: ‘союз’,
‘PART’: ‘частица’,
‘INTJ’: ‘межд.’
В качестве алгоритма обучения я выбрал метод опорных векторов (SVM). Если вы не знакомы с SVM или алгоритмами машинного обучения в общем, то представьте, что SVM это некий черный ящик, который принимает на вход характеристики данных, а на выходе классификацию по заранее заданным категориям. В качестве характеристик мы зададим, например, окончание слова, а в качестве категорий — части речи. 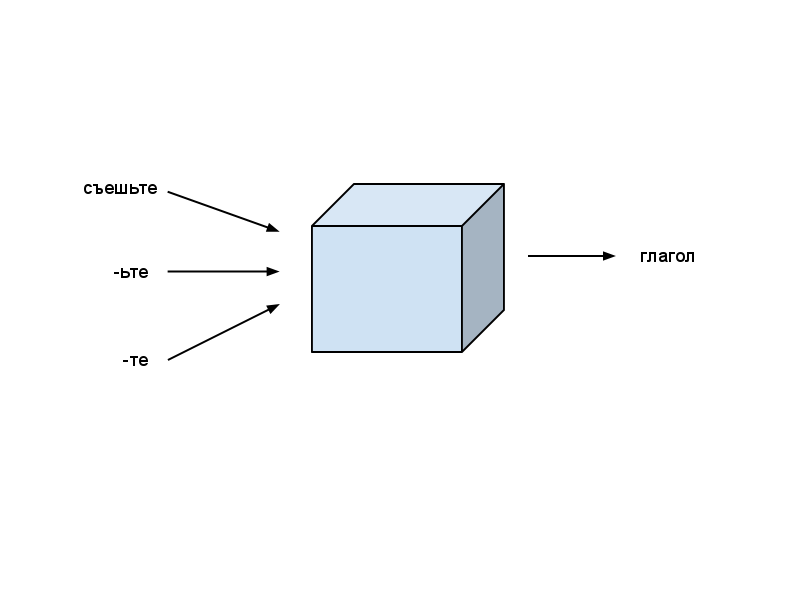
Чтобы черный ящик автоматически распознавал часть речи, для начала его нужно обучить, т.е. дать много характеристик примеров на вход, и соответствующие им части речи на выход. SVM построит модель, которая при достаточных данных будет в большинстве случаев корректно определять часть речи.
Даже в академических целях реализовать SVM лень, поэтому воспользуемся готовой библиотекой LIBLINEAR на С++, которая имеет обертку для питона. Для обучения модели используем функцию train(prob, param), которая принимает в качестве первого аргумента задачу: problem(y, x), где y — это массив частей речи для каждого примера из массива x. Каждый пример представлен в свою очередь вектором характеристик. Чтобы добиться такой постановки задачи, нам нужно сначала соотнести каждую часть речи и каждую характеристику с неким числовым номером. Например:
- Читаем файл корпуса и для каждого слова определяем его характеристики: само слово, окончание (2 и 3 последних буквы), приставка (2 и 3 первые буквы), а также части речи предыдущих слов
- Каждой части речи и характеристике присваиваем порядковый номер и создаем задачу для обучения SVM
- Обучаем модель SVM
- Используем обученную модель для определения части речи слов в предложении: для этого каждое слово нужно опять представить в виде характеристик и подать на вход SVM модели, которая подберет наиболее подходящий класс, т.е. часть речи.
Реализация
С исходными кодами можете ознакомиться здесь: github.com/irokez/Pyrus/tree/master/src
Корпус
Хотя для наших целей пойдет и небольшая выборка из корпуса, доступная тут: www.ruscorpora.ru/download/shuffled_rnc.zip
Файлы в полученном архиве нужно пропустить через утилиту convert-rnc.py, которая переводит текст в UTF-8 и исправляет XML разметку. После этого, возможно, еще нужно пофиксить XML вручную (xmllint вам в помощь). Файл rnc.py содержит простой класс Reader для чтения нормализованных XML файлов нац. корпуса.
Метод Reader.read(self, filename) читает файл и выдает список предложений:
Обучение и разметка текста
cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
Файл pos.py содержит два основных класса: Tagger и TaggerFeatures. Tagger — это, собственно, класс, который осуществляет разметку текста, т.е. определяет для каждого слова его часть речи. Метод Tagger.train(self, sentences, labels) принимает в качестве аргументов список предложений (в том же формате, что и выдает rnc.Reader.read), а также список частей речи для каждого слова, после чего обучает SVM модель, используя библиотеку LIBLINEAR. Обученная модель впоследствии сохраняется (через метод Tagger.save), чтобы не обучать модель каждый раз. Метод Tagger.label(self, sentence) производит разметку предложения.
Класс TaggerFeatures предназначен для генерации характеристик для обучения и разметки. TaggerFeatures.from_body() возвращает характеристику по форме слова, т.е. возвращает ID слова в корпусе. TaggerFeatures.from_suffix() и TaggerFeatures.from_prefix() генерируют характеристики по окончанию и приставке слов.
Чтобы запустить обучение модели, был написан скрипт train.py, который читает файлы корпуса при помощи rnc.Reader, а затем вызывает метод Tagger.train:
После того, как модель обучена и сохранена, мы, наконец, получили скрипт для разметки текста. Пример использования показан в test.py:
Работает так:
$ src/test.py «Съешьте еще этих мягких французских булок, да выпейте же чаю»
[(‘Съешьте’, ‘глаг.’), (‘еще’, ‘нареч.’), (‘этих’, ‘местоим. прил.’), (‘мягких’, ‘прил.’), (‘французских’, ‘прил.’), (‘булок,’, ‘сущ.’), (‘да’, ‘союз’), (‘выпейте’, ‘глаг.’), (‘же’, ‘частица’), (‘чаю’, ‘сущ.’)]
Тестирование
Для оценки точности классификации работы алгоритма, метод обучения Tagger.train() имеет необязательного параметр cross_validation, который, если установлен как True, выполнит перекрестную проверку, т.е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
Заключение и планы на будущее
В общем, было интересно поработать с нац. корпусом. Видно, что работа над ним проделана большая, и в нем содержится большое количество информации, которую хотелось бы использовать в полной мере. Я послал запрос на получение полной версии, но ответа пока, к сожалению, нет.
Полученный скрипт разметки можно легко расширить, чтобы он также определял другие морфологические категории, например, число, род, падеж и др. Чем я и займусь в дальнейшем. В перспективе хотелось бы, конечно, написать синтаксический парсер русского языка, чтобы получить структуру предложения, но для этого нужна полная версия корпуса.
10 сервисов, которые быстро посчитают количество символов в тексте

Вы знаете, что работу копирайтера оценивают по количеству знаков. Нужно писать столько, сколько указано в ТЗ. Иначе заказчик может не заплатить. Сегодня я расскажу вам о 10 простых способах, как посчитать количество символов в тексте.

Когда я только начинала работать копирайтером, измеряла тексты в Word. Неплохая программка, но есть инструменты и получше.
Поделюсь с вами одним секретом. Опытный автор не всегда пользуется Word. Я и сама стала проверять только онлайн. “Вордом” подсчитываю редко.
Я научу вас пользоваться крутыми знакосчиталками. Вы освоите их меньше чем за полчаса. Поехали!
1. Text
Копирайтерам знаком Text.ru. Если еще не знаете, то в скором времени познакомитесь. Там воду можно проверить и заспамленность.
Он показывает статистику: объем статьи в знаках с пробелами и без, сколько слов.
Проверить можно на главной странице или в разделе SEO-анализа.
Чтобы узнать количество символов, зайдите на главную страницу и вставьте текст в поле.
Необязательно кликать на “Проверить на уникальность”. Количество символов появится снизу.
Из-за чего стоит пользоваться:
- подробный анализ по SEO-параметрам, уникальности;
- сохранение результата у зарегистрированных пользователей.
Text подходит всем. Им пользуются как престижные компании, так и начинающие копирайтеры.
2. Advego
Никогда бы не назвала Advego считалкой. Но это так. Я смотрю на счетчик символов, когда проверяю тошнотность по просьбе заказчика. Зачем куда-то ходить, если все рядом.
Сейчас покажу, как правильно определить длину письменного творения в Advego бесплатно.
Заходите на Advego. Кликаете по вкладке “SEO-анализ текста”.

Вставляете текст в рабочее поле.
Считалка сразу покажет объем. Чтобы заглянуть в статистику, нажмите “Проверить”.
За что нравится:
- быстро работает;
- сразу проверяет заспамленность, объем статьи.

3. Word
Все пути начинаются с Word. Там мы пишем, проверяем правописание, учимся считать знаки.
Microsoft создали прекрасный счетчик. Но когда я перешла на печать в Evernote, сервисах Google, стало немного неудобно пользоваться “Вордом”. Программа запускается дольше, чем онлайн-знакосчиталка.
Какой у вас Microsoft Office Word? Если 2003 года, то калькулятор слов в тексте ищите в меню сервиса – статистике.
С версией 2007 года проще. Видите вверху вкладку “Рецензирование”? Хорошо, заходите туда.

Там рядом с правописанием есть кнопка статистики. На ней изображены ABC123.

Если не хочется “бегать” по вкладкам, могу предложить путь короче.
В строке состояния внизу находится панель “Число слов”. Жмем.

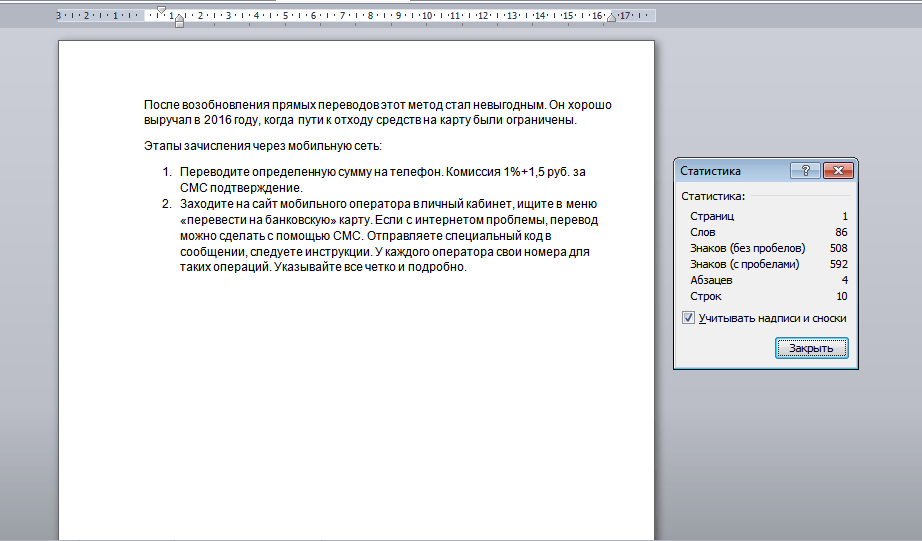
Появляется окошко со статистикой.
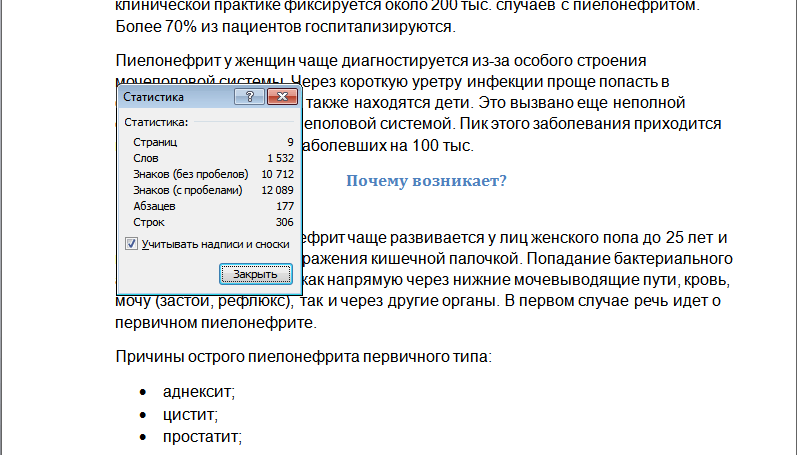
Теперь нам известно число:
- знаков без пробелов и с ними;
- строк;
- абзацев;
- страниц.
Чтобы узнать количество символов отдельного фрагмента, скопируйте и так же нажмите на статистику.
Можно назначить сочетание горячих клавиш для проверки. Зажимаем Ctrl, Alt и + одновременно. Всплывает меню. Там напротив сочетания клавиш выбираем кнопку “Настроить”. Выбираем нужную команду, вводим, например, “Shift + D”.
- можно пользоваться в офлайн-режиме;
- удобно, если пишете там.
Если нет возможности поставить Word, скачайте OpenOffice. По умолчанию окно с подсчетами возникает при нажатии “Ctrl + Shift + G”.
4. Simvoli.net
Simvoli.net – сервис для подсчета слов онлайн. Никаких установок, простой интерфейс. Там есть полезные фишки, которые помогут сэкономить копирайтеру время.
Считать объем статьи здесь – одно удовольствие. Чтобы вы наслаждались этой знакосчиталкой со мной, я расскажу, как ей пользоваться.
Переходим на сайт. Вставляем статью в поле. Кликаем “Посчитать + анализ”.
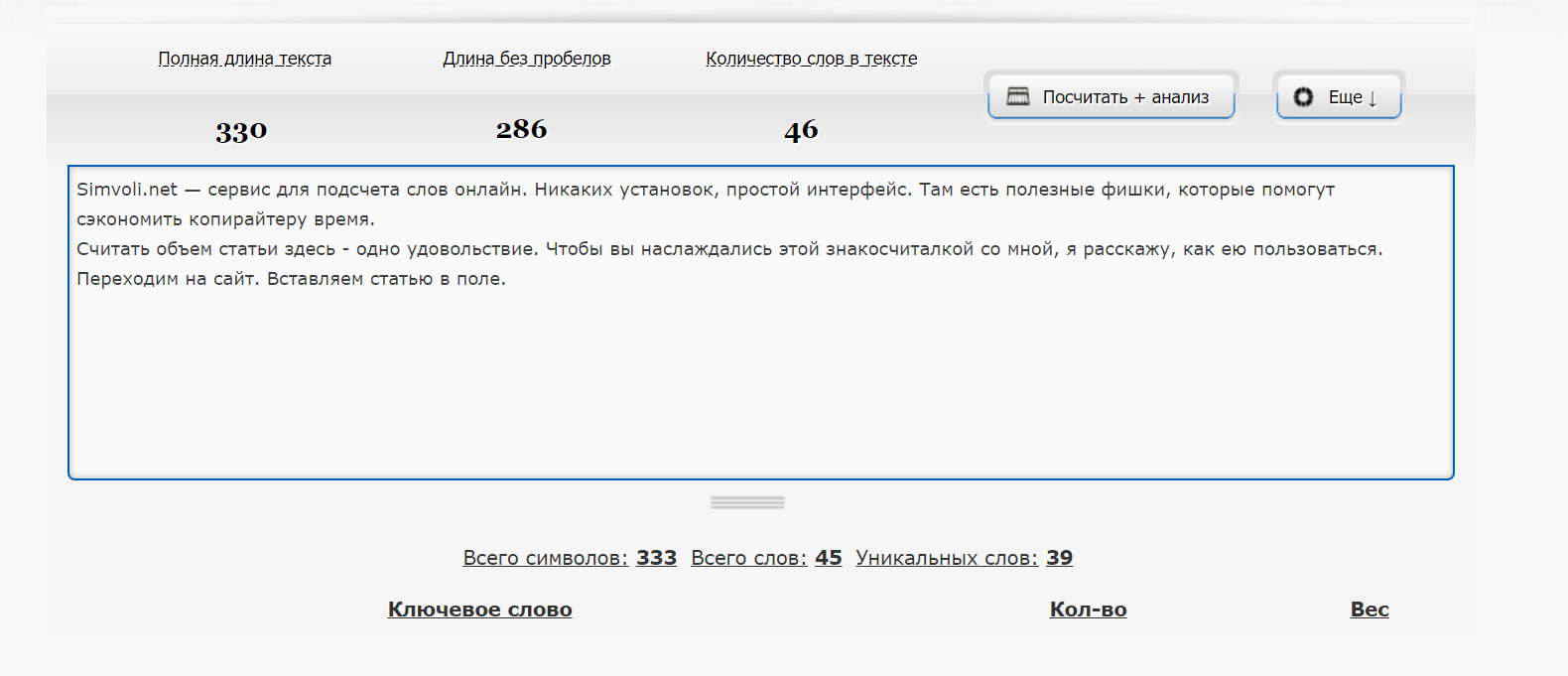
Нам удалось узнать, сколько слов в тексте. Но это не все. Под кнопкой “Еще” скрывается несколько полезных штучек для авторов.
Что можно сделать с текстом:
- Изменить верхний регистр. Все слова в начале предложения будут с большой буквы.
- Поменять на нижний регистр. Заглавные буквы заменяются на маленькие.
- Полностью озаглавить статью. Каждое слово начинается с верхнего регистра.
- Перевести на латинские буквы. Текст будет на русском, только будет переписан английскими буквами.
- Очистить рабочее поле. Не придется долго и нудно выделять всю статью, чтобы удалить. Одно нажатие – чисто.
Сервис служит авторам верой и правдой более 3 лет. Если не нужно проверять работу по SEO-параметрам, он идеально подойдет.
5. VIP-контент
VIP-контент способен заменить Word и даже в чем-то превосходит его. Кроме счета букв без регистрации, сервис имеет много интересных функций, которые понадобятся копирайтеру.
Проверка количества знаков простая, удобная, информативная.
Кликаем на “Подсчитать”. Через несколько секунд подробная статистика уже перед глазами.
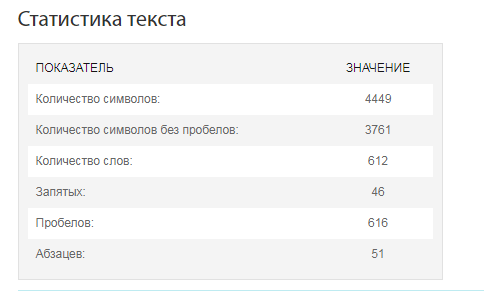
Информации достаточно, чтобы отправить работу заказчику или править ее. С количеством запятых они угадали. Для себя интересно, сколько сложных предложений, знаков препинания уже успели наставить.
Сервис также превращает текст в изображение. Я и не знала, что онлайн-сервисы способны на такие чудеса. Вдруг вам бегло надо будет добавить работу в портфолио или сделать пример в статье.
Копируем текст в поле. Кликаем “Преобразовать в картинку”. Она скачивается в нужную нам папку.
На выходе получаем такой симпатичный результат.

Эта функция может понадобиться не только копирайтеру, но и заказчику, составляющему ТЗ. Например, чтобы показать образец статьи.
В конце картинки всегда стоит логотип сайта. Поэтому либо его убирать (обрезать, замазать), либо жить с этим.
Другие функции сайта:
- проверка на орфографические ошибки – слабая, не полагайтесь на нее;
- удаление повторов слов;
- исключение html-тегов;
- вырезание фрагмента текста;
- очистка формы – сэкономите время при удалении текста.
6. Google Документы
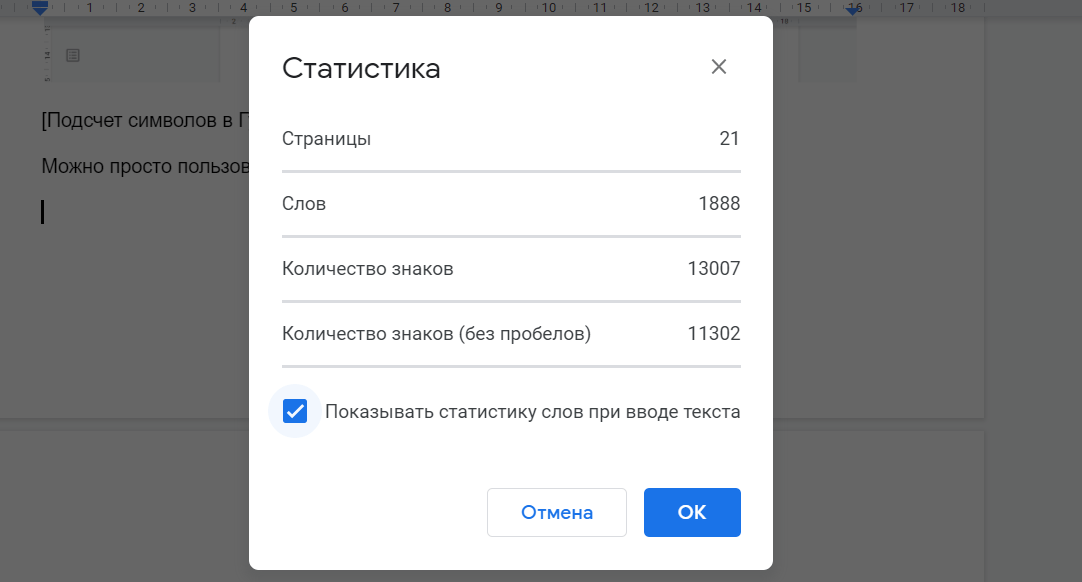
Google Документы необходимо открыть в браузере или скачать приложение на мобильный. Заходим. Пишем или вставляем уже готовую статью. Выбираете вверху “Инструменты” → “Статистика”.

Можно просто пользоваться комбинацией клавиш “Ctrl + Shift + C”.
Боитесь превысить объем по ТЗ? Но проверять каждые 5 минут, сколько успели написать, – лень? Тогда в том же окошке с количеством знаков отметьте галочкой “Показывать статистику слов при вводе текста”.
7. Excel
В Excel можно узнать количество знаков в определенных ячейках. К сожалению, только у версий 2013, 2016 и 2019 годов есть эта функция.
Напишите в строке формул “=ДЛСТР(название ячейки)”.

Нажимаем Enter в строке формул. В другой ячейке видим, сколько символов в предложении.

8. Seostop
Seostop – это онлайн-считатель символов с пробелами и без. С ним не придется нагружать ноутбук лишним ПО. Пожалейте его, вы и так стучите по клавиатуре несколько тысяч раз в день.
Не ищите там дополнительных функций. Мы ведь пришли знаки считать, а не глубокий анализ делать. Для этого есть специальные сервисы: Advego, Text и др. Нам же нужна простая знакосчиталка.
На сайте в разделе “Полезное” находим “Счетчик знаков”. Идем туда.

Считать здесь очень быстро – это просто. Вставляете текст в поле, а Seostop автоматически показывает количество символов без пробелов и с ними. Никаких кнопок нажимать не нужно.
Если этого недостаточно и вы хотите проверить текст на ошибки, то отправляйтесь в Орфограммку. Там такие правки можно сделать, что заказчик влюбится в вашу статью.

9. Copywritely
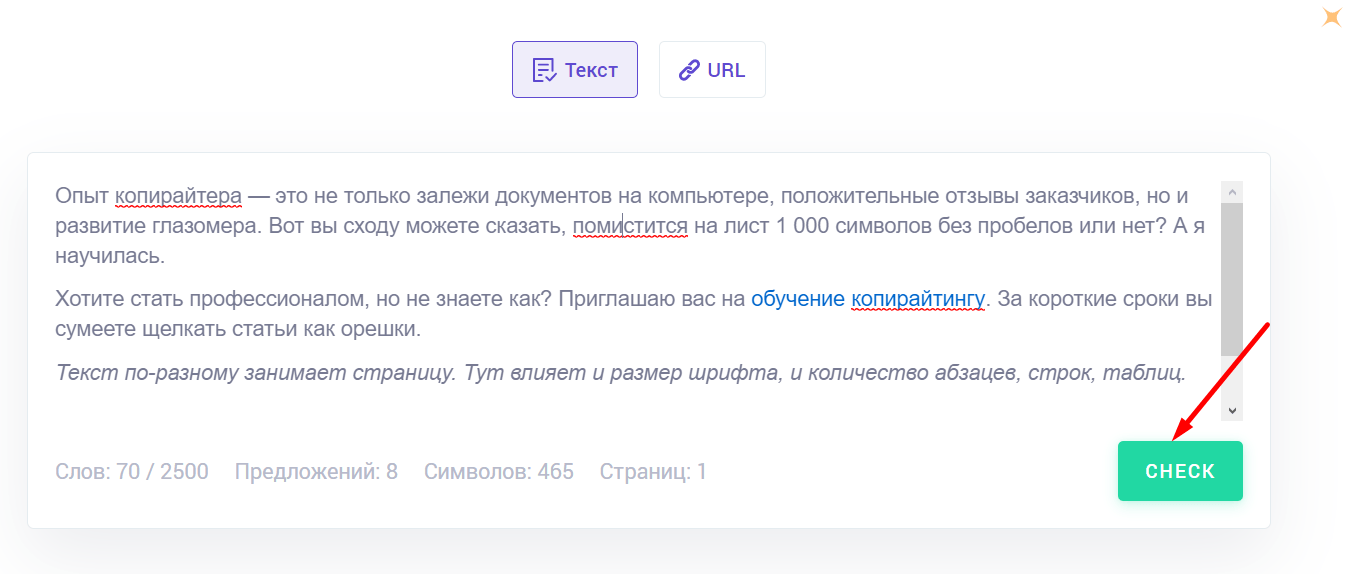
Copywritely считает не только, сколько знаков вы написали, но еще и предложения, слова, страницы. Еще он обнаруживает орфографические ошибки.
Для подсчета не нужно далеко ходить. Заходите на сайт. Добавляете то, что хотите проверить, в текстовое поле. Мгновенно видите результат в нижней строке.
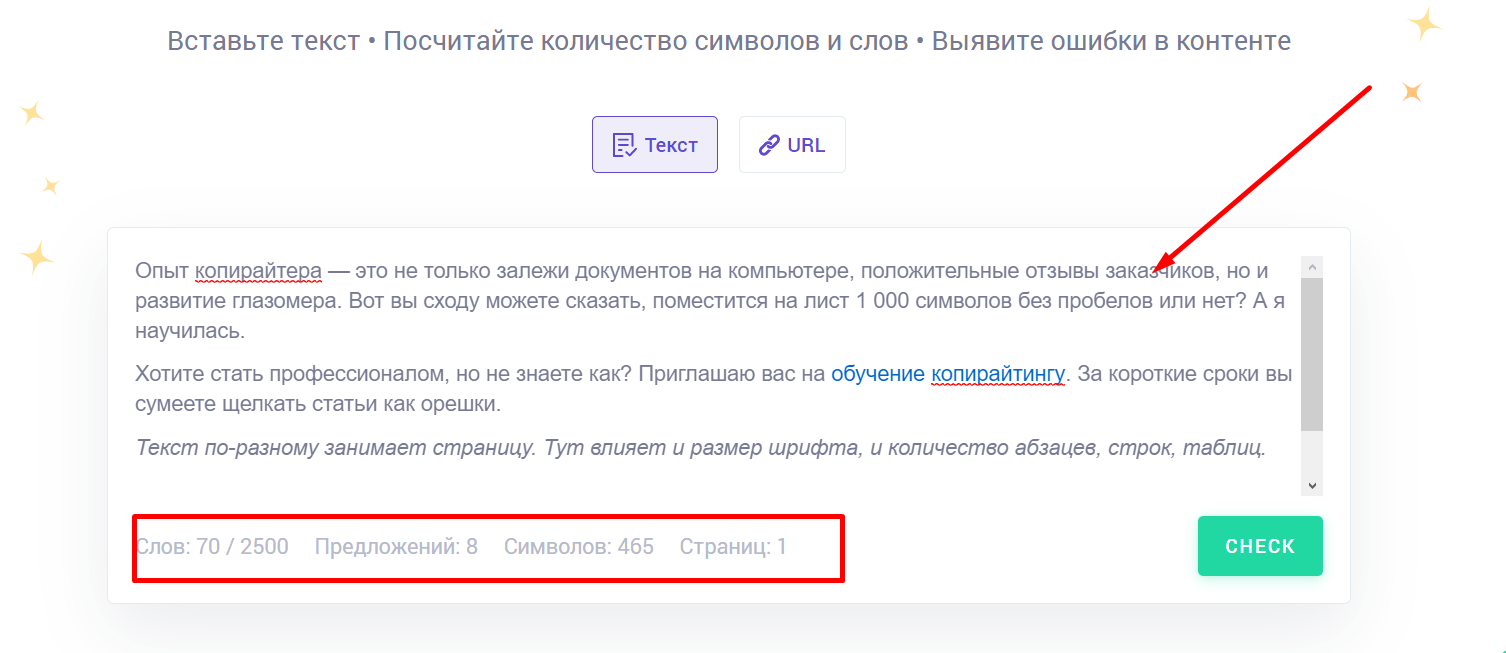
Если хотите проверить на ошибки, уникальность и тошноту, тогда нажмите “Check”.
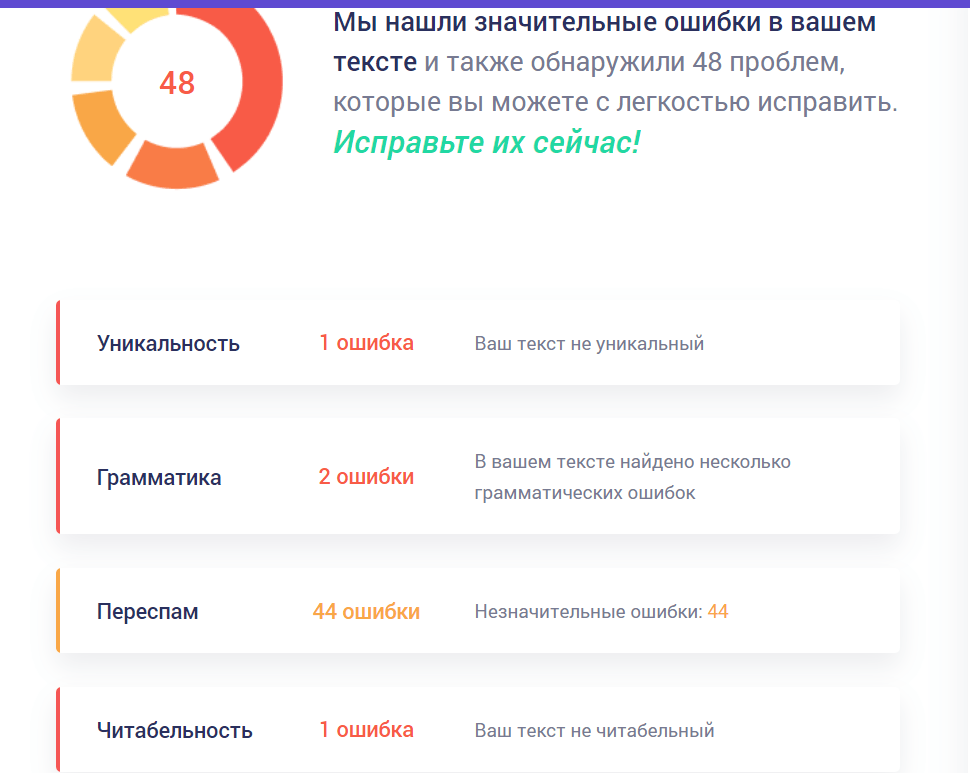
В результате получаем подробную статистику:
10. Slogi
Slogi – необычный инструмент, который скорее пригодится школьникам и студентам. Он разбивает слово на слоги и считает их.
Введите слово в строчку и кликните на кнопку “по слогам →”.

Сколько на одной странице букв, символов, слов?
Опыт копирайтера – это не только залежи документов на компьютере, положительные отзывы заказчиков, но и развитие глазомера. Вот вы с ходу можете сказать, поместится на лист 1 000 символов без пробелов или нет? А я научилась.
Текст по-разному занимает страницу. Тут влияет и размер шрифта, и количество абзацев, строк, таблиц.
Чтобы вы сэкономили свое драгоценное время, я подскажу, сколько текста помещается на страницах и т. п. Без считалок все равно не обойтись, но вы хотя бы будете проверять уже в конце, а не постоянно поглядывать на счетчик.
Вы научитесь ценить свой труд. Потому что новичкам сложно понять: 1 000 символов – это много или мало, стоит ли это 20 руб. или лучше обойти заказ стороной.
1 000 знаков текста занимает примерно 65 % одного листа Word.
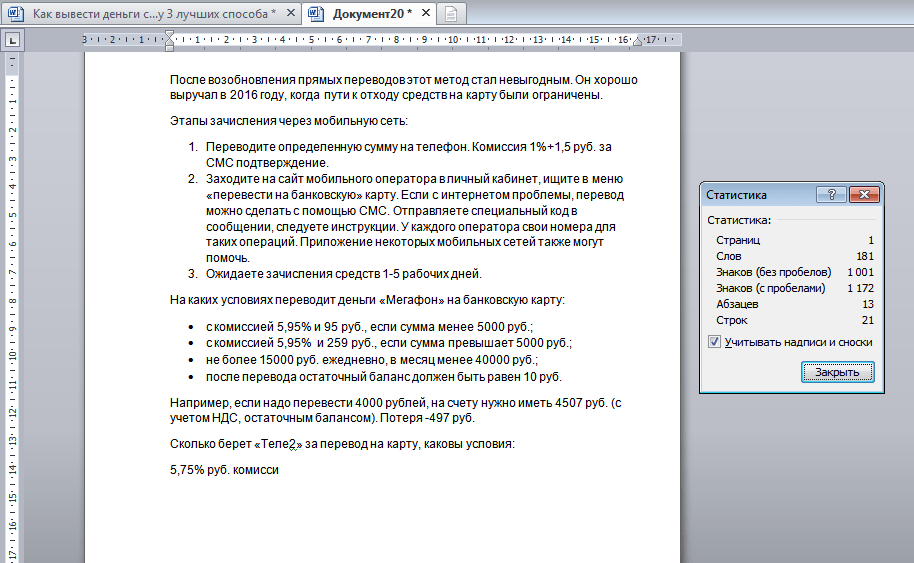
Сколько знаков на странице А4. Чтобы заполнить ее полностью, понадобится 1 889 знаков, написанных Arial 12.
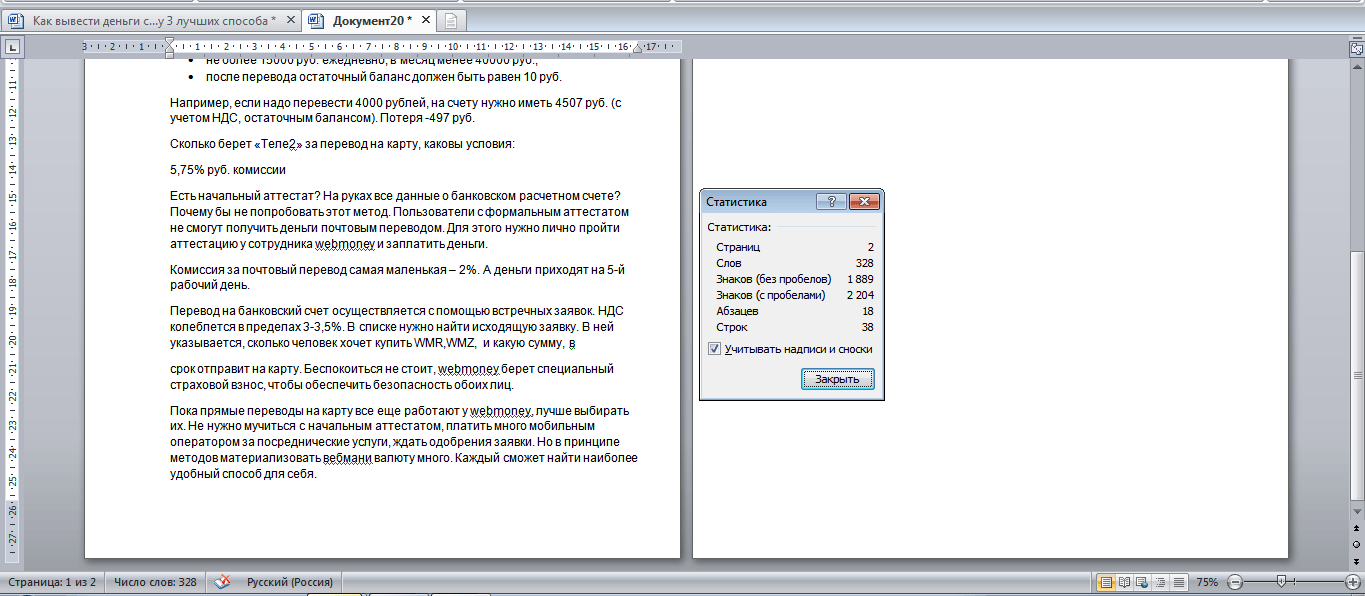
Краткий отзыв или описание товара занимает страничку на 20 %.
Теперь вы знаете, что тестовое задание в 1 000 печатных символов без пробелов – это не так много. Заказчики часто дают маленькие объемы, чтобы проверить вас на деле.
Заключение
Каждому автору нужно следить за размером текста. От него зависит оплата. Конечно, есть добрые заказчики, которые доплачивают за объем, но это исключение. Вы можете разочаровать работодателя, если выйдете за рамки ТЗ.
Удобнее пользоваться биржами проверки текста. Обычно, там можно сразу проверить на уникальность, ошибки, воду и определить объем.
Напишите в комментариях, чем пользуетесь для подсчета символов, какой сайт понравился.
Хотите постоянно узнавать о полезных фишках для копирайтинга? Подписывайтесь, мы ждем вас.
Семантический анализ текста istio
Семантический анализ текста от Istio оценивает его насыщенность ключевыми словами, водность, заспамленность. Поисковые системы определяют качество и релевантность текстового контента по словам и словосочетаниям, из которых он состоит.
Если в тексте достаточно тематических ключевых фраз, то поисковики оценят его как хороший. Статьи, в которых преобладает вода и мало ключевых слов, не попадают на первые страницы выдачи. Контент, перенасыщенный ключевиками, относится к переспаму, его поисковые системы показывают редко.
Что показывает семантический анализ текста?
SEO-анализ текста позволяет оценить статью по показателям процента ключевых слов, количеству стоп-слов. Сервис показывает:
- плотность ключевиков, их процентное соотношение в ядре и в тексте;
- объем статьи: количество слов и символов (с пробелами и без);
- словарь: общее количество единиц, словарь ядра;
- частотность слов, выводит топ-10 наиболее употребляемых;
- язык статьи и приблизительную тематику;
- процент воды.
Семантический анализ от Istio позволяет автоматически посчитать количество символов, оценить тошнотность и водность. Для удобства пользователей сервис подсвечивает ключевики и воду, создает наглядную карту частотных слов.
Проверка тошноты статьи
Параметр тошноты текста показывает его заспамленность ключевиками. Чем их больше, тем выше показатель. Поисковые системы расценивают такую статью как некачественную, в выдачу она не попадает.
Чтобы проверить тошноту текстового контента, в поле «Выделение ключей» нужно указать запросы. Сервис выделит их цветной рамкой.

В нижней части страницы отображается количество и процентное соотношение ключевых фраз в ядре и тексте.

В пункте «Карта текста» пользователь наглядно увидит, какие единицы часто повторяются в статье. Можно визуально оценить, на каком расстоянии находятся повторяющиеся фразы.

Водность текста
Анализ воды текста отображает наличие в статье стоп-слов, фразеологизмов, соединительных единиц, не несущих смысловой нагрузки. Если их удалить, контент не потеряет смысла и станет качественнее.
Сервис выделяет цветом слова без смысловой нагрузки. Это единицы с необъективной оценкой, не несущие конкретной информации, а также усилители. Выделенные фразы рекомендуется удалить или заменить.

Небольшое количество незначимых единиц естественно для любого текста. Показатель нужно сводить к минимуму, чтобы получать качественный контент без воды для поисковой системы.
Количество символов, частотность слов
В нижней части страницы размещен анализ количества символов (со стоп-словами и без них), частотность единиц текста. В отдельное поле вынесена проверка частоты ключевиков. Оценивается их процентное соотношение ко всей статье и только к значимым фразам.
Для того чтобы проверить текстовый контент на показатели воды, тошноты и частоты фраз, необходимо:
- выбрать пункт «Анализ текста», вставить статью в поле;
- в пункте «Список ключевых слов» указать их, если нужно проверять этот параметр;
- нажать на кнопку «Выделение ключей», чтобы увидеть их расположение наглядно;
- выбрать пункт «Карта» – крупным шрифтом сервис выделяет наиболее частотные единицы;
- кликнуть на «Водность», чтобы подсветить незначимые фразы.
Работать с ресурсом можно без регистрации и авторизации. На Istio нет ограничений по символам для проверки.